Настроить SQL Server — полдела. Без регулярного обслуживания база деградирует. Индексы фрагментируются, статистика устаревает, журнал транзакций разрастается, и через полгода «нормально настроенный» сервер работает так же медленно, как дефолтный.
Мы видели базу, которую настроили идеально при внедрении: MAXDOP, память, TempDB — всё по чек-листу. Через год — жалобы на производительность. Причина: ни одного регламентного задания. За год фрагментация ключевых индексов достигла 95%, статистика не обновлялась ни разу, DBCC CHECKDB никто не запускал. Повезло, что повреждений данных не было — но это именно везение.
Ниже — конкретный план обслуживания с расписанием, скриптами и объяснением, зачем нужен каждый пункт.
Общая картина: что и когда
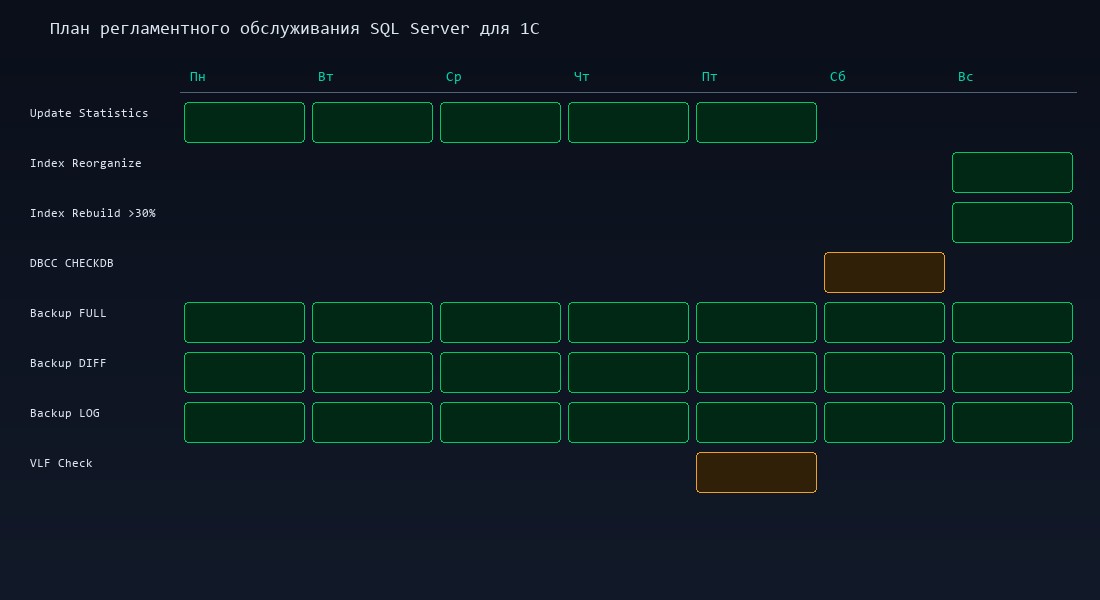
План строится от частого к редкому. Бэкапы — непрерывно. Статистика — ежедневно. Индексы — еженедельно. Проверка целостности — еженедельно. Каждый элемент решает конкретную проблему.
Обновление статистики: ежедневно
Статистика — это информация о распределении данных в таблицах. Оптимизатор запросов SQL Server использует её для построения плана выполнения. Устаревшая статистика = плохой план = медленный запрос.
SQL Server обновляет статистику автоматически, когда количество изменённых строк превышает порог. Но для больших таблиц (1С:ERP — таблицы в десятки миллионов строк) порог может не срабатывать достаточно часто. Результат: оптимизатор строит план на основе данных недельной давности.
-- Обновление статистики для всех таблиц базы 1С
EXEC sp_MSforeachtable 'UPDATE STATISTICS ? WITH FULLSCAN';FULLSCAN означает полное сканирование таблицы для расчёта статистики. Это точнее, чем выборочное (SAMPLE), но дольше. Для ночного регламента — оптимальный вариант. На базе 50-100 ГБ обновление с FULLSCAN занимает 10-30 минут.
Альтернатива для очень больших баз — SAMPLE 30 PERCENT. Менее точно, но в 3-4 раза быстрее.

Реальный случай: отчёт по продажам за месяц формировался 45 секунд. После обновления статистики — 3 секунды. Оптимизатор выбирал Index Scan вместо Index Seek, потому что статистика говорила, что в таблице 500 000 строк, а реально было 8 миллионов.
Обслуживание индексов: еженедельно
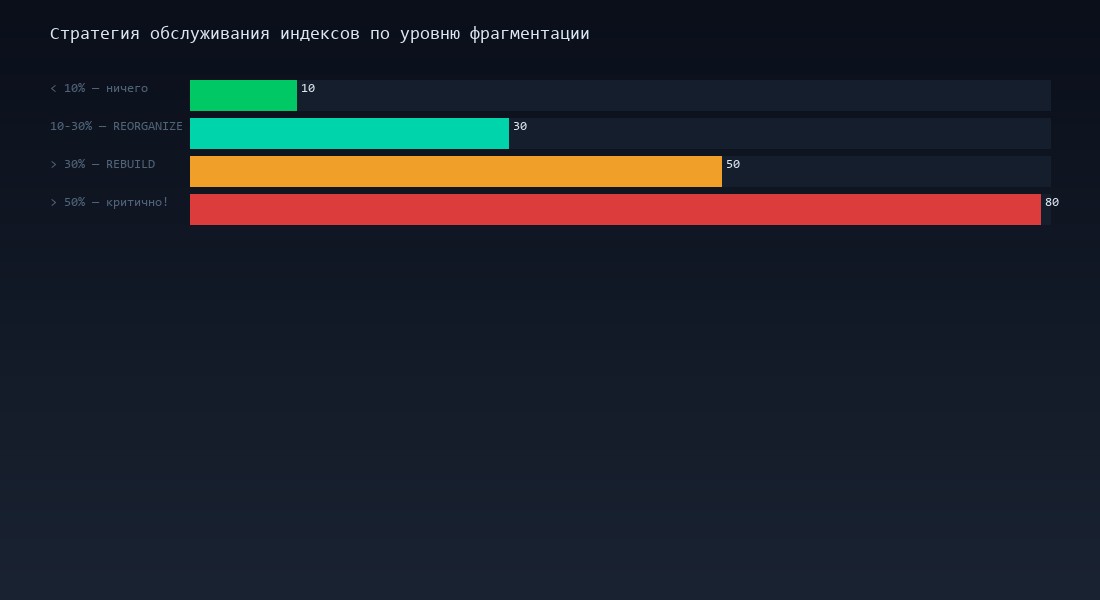
Фрагментация индексов — это когда логический порядок страниц в индексе не совпадает с физическим порядком на диске. При последовательном чтении SQL Server вынужден прыгать по диску вместо чтения подряд. На SSD эффект менее заметен, но всё равно есть — из-за увеличенного объёма данных для чтения.
Стратегия по уровню фрагментации:
- Менее 10% — ничего не делать. Нормальный уровень для активной базы
- 10-30% — REORGANIZE. Онлайн-операция, не блокирует таблицу, можно выполнять в рабочее время при необходимости
- Более 30% — REBUILD. Пересоздаёт индекс с нуля. Блокирует таблицу (в Standard Edition), поэтому только в нерабочее время
-- Скрипт обслуживания индексов
DECLARE @sql NVARCHAR(MAX);
SELECT @sql = STRING_AGG(
CASE
WHEN avg_fragmentation_in_percent BETWEEN 10 AND 30
THEN 'ALTER INDEX [' + i.name + '] ON [' + OBJECT_SCHEMA_NAME(ips.object_id) + '].[' + OBJECT_NAME(ips.object_id) + '] REORGANIZE;'
WHEN avg_fragmentation_in_percent > 30
THEN 'ALTER INDEX [' + i.name + '] ON [' + OBJECT_SCHEMA_NAME(ips.object_id) + '].[' + OBJECT_NAME(ips.object_id) + '] REBUILD;'
END, CHAR(13)
)
FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, 'LIMITED') ips
JOIN sys.indexes i ON ips.object_id = i.object_id AND ips.index_id = i.index_id
WHERE ips.avg_fragmentation_in_percent > 10
AND ips.page_count > 1000
AND i.name IS NOT NULL;
EXEC sp_executesql @sql;Фильтр page_count > 1000 — индексы на маленьких таблицах (менее 1000 страниц) обслуживать бессмысленно. SQL Server и так читает их целиком за одну операцию.
Время выполнения зависит от размера базы и степени фрагментации. Для базы 50 ГБ при первом запуске (после года без обслуживания) — может занять 2-4 часа. При регулярном еженедельном обслуживании — 20-40 минут.
DBCC CHECKDB: еженедельно
DBCC CHECKDB — проверка физической и логической целостности базы данных. Единственный способ обнаружить повреждение данных до того, как оно проявится ошибкой при работе пользователя.
Повреждения происходят по разным причинам: сбой питания, ошибка контроллера дисков, баг SQL Server. Без CHECKDB вы узнаете о проблеме, когда бухгалтер не сможет открыть документ. А к этому моменту все бэкапы за последние N дней тоже могут содержать повреждение — если оно произошло давно.
-- Проверка целостности
DBCC CHECKDB ('your_1c_db') WITH NO_INFOMSGS, ALL_ERRORMSGS;NO_INFOMSGS — подавляет информационные сообщения, оставляя только ошибки. ALL_ERRORMSGS — выводит все ошибки, а не только первые 200.
Время выполнения: пропорционально размеру базы. Примерно 1 ГБ в минуту на современном SSD-хранилище. База 100 ГБ — около 1.5-2 часов. Планируйте на субботу ночью.
Если CHECKDB обнаружил ошибки — не пытайтесь чинить автоматически. REPAIR_ALLOW_DATA_LOSS (название говорит само за себя) может удалить данные. Первое действие — восстановить базу из последнего чистого бэкапа.
Бэкапы: непрерывно
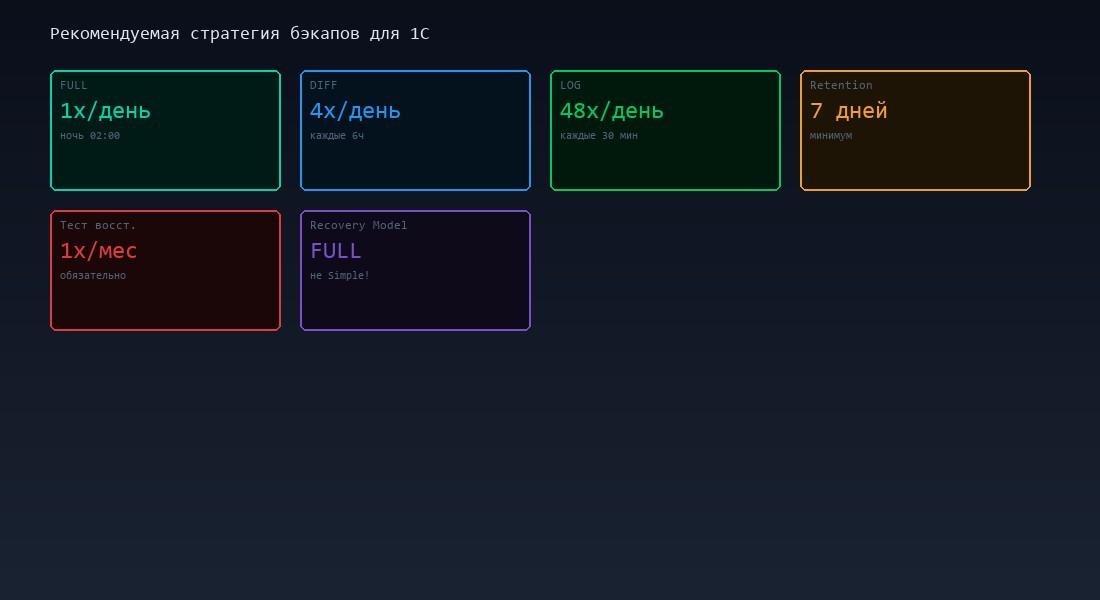
Без бэкапов всё остальное обслуживание бессмысленно. Нашли повреждение через CHECKDB, но бэкапа нет? Потеряли данные. Рекомендуемая стратегия для рабочей базы 1С:
Recovery Model = FULL. Не Simple. Simple означает, что журнал транзакций усекается автоматически, и вы не можете восстановить базу на произвольный момент времени. Только на момент последнего бэкапа. Если последний бэкап был в 2:00, а авария в 17:00 — потеряны данные за 15 часов.
FULL backup: ежедневно, ночью. Полная копия базы.
DIFFERENTIAL backup: каждые 4-6 часов. Содержит только изменения с последнего FULL. Занимает меньше места, восстанавливается быстрее.
LOG backup: каждые 15-30 минут. Копия журнала транзакций. Позволяет восстановить базу на любой момент с точностью до последнего бэкапа лога. При LOG каждые 15 минут максимальная потеря — 15 минут данных.
-- FULL backup (ежедневно, 02:00)
BACKUP DATABASE [your_1c_db]
TO DISK = 'D:\Backups\your_1c_db_full.bak'
WITH COMPRESSION, CHECKSUM, INIT;
-- DIFF backup (каждые 6 часов)
BACKUP DATABASE [your_1c_db]
TO DISK = 'D:\Backups\your_1c_db_diff.bak'
WITH DIFFERENTIAL, COMPRESSION, CHECKSUM, INIT;
-- LOG backup (каждые 30 минут)
BACKUP LOG [your_1c_db]
TO DISK = 'D:\Backups\your_1c_db_log.trn'
WITH COMPRESSION, CHECKSUM, INIT;COMPRESSION — сжатие бэкапа. Уменьшает размер в 3-5 раз, почти не влияет на скорость.
CHECKSUM — контрольная сумма. При восстановлении SQL Server проверит целостность бэкапа.
Retention — минимум 7 дней. Если повреждение обнаружится через 3 дня, у вас будет запас чистых бэкапов. Храните на отдельном диске или на сетевом хранилище — бэкап на том же диске, что и база, бесполезен при отказе диска.
Контроль VLF: ежемесячно
VLF (Virtual Log Files) — внутренняя структура журнала транзакций. Каждое расширение журнала создаёт новые VLF. Если autogrow стоит маленький (10 МБ по умолчанию), за год количество VLF может вырасти до десятков тысяч. Это замедляет бэкапы, восстановление и операции с журналом.
-- Проверка количества VLF
DBCC LOGINFO('your_1c_db');
-- Посчитать строки в результате = количество VLF
-- Или в SQL Server 2016+:
SELECT database_id, total_vlf_count
FROM sys.dm_db_log_stats(DB_ID());Норма — до 200-300 VLF. Если больше 1000 — нужна очистка. Процедура: бэкап лога → SHRINKFILE до минимума → расширение файла до нужного размера одной операцией.
-- Уменьшение VLF (выполнять в нерабочее время)
BACKUP LOG [your_1c_db] TO DISK = 'NUL';
DBCC SHRINKFILE (your_1c_db_log, 1); -- сжать до 1 МБ
ALTER DATABASE [your_1c_db]
MODIFY FILE (NAME = your_1c_db_log, SIZE = 8192MB); -- вернуть размерПосле этой операции журнал будет состоять из минимального числа VLF оптимального размера.
Расписание SQL Agent
Все регламенты оформляются как задания SQL Server Agent. Расписание:
- Будни, 01:00 — UPDATE STATISTICS WITH FULLSCAN
- Воскресенье, 02:00 — обслуживание индексов (REORGANIZE + REBUILD)
- Суббота, 01:00 — DBCC CHECKDB
- Ежедневно, 02:00 — FULL backup
- Каждые 6 часов — DIFF backup
- Каждые 30 минут — LOG backup
- Первая пятница месяца — проверка VLF, мониторинг размеров файлов
Критически важно: настройте алертинг. SQL Agent может отправлять email при ошибке задания. Бэкап, который молча падает каждую ночь, — хуже, чем отсутствие бэкапа. С отсутствующим хотя бы понятно, что его нет.
Алертинг: не молчите об ошибках
Настроить регламенты — недостаточно. Нужно знать, когда они падают. SQL Agent поддерживает уведомления через Database Mail. Настройте отправку email при ошибке любого задания.
Минимальная настройка: создайте оператор (Operator) в SQL Agent с email-адресом администратора. В каждом задании на вкладке Notifications включите «Email operator on failure».
Что мониторить в первую очередь:
- Бэкап не выполнился. Критично. Если FULL backup не выполнялся 2 дня — это аварийная ситуация. Через день потерянных данных может быть столько, что восстановление из позавчерашнего бэкапа уже неприемлемо
- DBCC CHECKDB нашёл ошибки. Критично. Повреждение данных не рассасывается само — только усугубляется. Чем раньше узнаете, тем меньше данных потеряете
- Обслуживание индексов не завершилось. Важно, но не критично. Обычно означает, что задание не уложилось в окно обслуживания. Нужно либо расширить окно, либо оптимизировать скрипт (например, обслуживать только индексы с фрагментацией >30%)
- Журнал транзакций заполнен. Критично. База перестаёт принимать транзакции. Причина — пропущенные бэкапы лога или застрявшая транзакция
Более продвинутый вариант — мониторинг через Prometheus + Grafana. SQL Server Exporter собирает метрики: размер базы, количество активных соединений, ожидания, статус заданий Agent. Дашборд показывает всё на одном экране, алерты уходят в Telegram.
Частые ошибки при настройке регламентов
Бэкап и обслуживание индексов в одно время. Оба задания нагружают диск. Если бэкап стартует в 02:00 и обслуживание индексов тоже в 02:00 — они будут конкурировать за I/O. Разнесите по времени: бэкап в 02:00, индексы в 04:00.
REBUILD индексов в рабочее время. REBUILD в Standard Edition берёт эксклюзивную блокировку на таблицу. Пользователи получат ошибки. Только в Enterprise Edition есть ONLINE = ON, который позволяет перестраивать индексы без блокировки. Если у вас Standard — только в нерабочее время.
SHRINKFILE по расписанию. Мы видели задание, которое каждую ночь делало SHRINKFILE для базы данных. Это фрагментирует все индексы и является полной противоположностью обслуживания. Никогда не шринкуйте базу по расписанию. Если нужно освободить место — сделайте один раз вручную, перестройте индексы, и оставьте файл достаточного размера.
Нет ротации бэкапов. Бэкапы пишутся на диск, но никто не удаляет старые. Через полгода диск заполнен, бэкап перестаёт выполняться. Добавьте шаг очистки: удаление бэкапов старше N дней:
-- Удаление бэкапов старше 7 дней
EXECUTE dbo.xp_delete_files
'D:\Backups',
'bak',
DATEADD(DAY, -7, GETDATE());Или через PowerShell / bash в шаге SQL Agent Job — что надёжнее и гибче.
Тест восстановления: ежемесячно
Отдельным пунктом — потому что его все пропускают. Бэкапы есть, расписание работает, журнал чистый. Всё хорошо — пока не попробуешь восстановить.
Раз в месяц: восстановить бэкап на тестовый сервер. Проверить, что база открывается, данные на месте, 1С подключается. Занимает 30 минут, экономит дни нервов при реальной аварии.
Без теста восстановления вы не знаете, работает ли ваш бэкап. А узнать это в момент аварии — поздно.