Стандартный сценарий обновления рабочей базы 1С: отключить всех пользователей, загрузить конфигурацию, обновить базу данных, запустить пользователей. На конфигурации ERP с парой сотен доработок это занимает 15-25 минут. Двадцать минут простоя. Бухгалтерия курит, склад стоит, кассиры ждут.
Мы добились сокращения до 3-5 минут. Не за счёт более быстрого железа, а за счёт разделения этапов и правильного порядка операций. Расскажем, как.
Наивный подход: всё в монополии
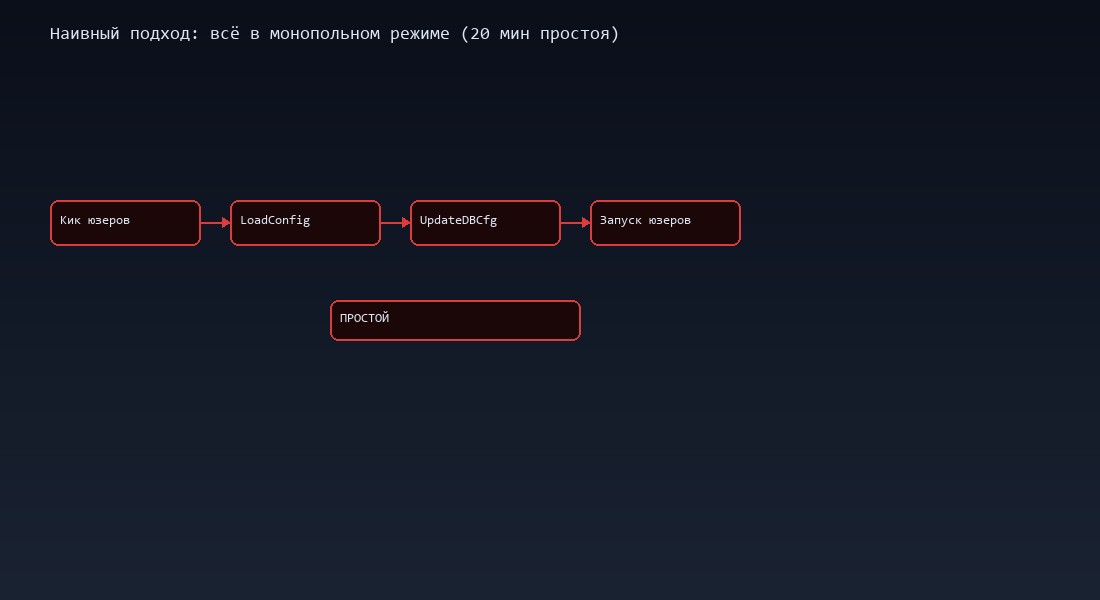
Типичный скрипт обновления выглядит так:
- Заблокировать новые подключения
- Отключить всех пользователей
- Запустить Конфигуратор: LoadConfigFromFiles (загрузка из XML)
- Запустить Конфигуратор: UpdateDBCfg (обновление БД)
- Снять блокировку, разрешить подключения
Проблема очевидна: LoadConfigFromFiles — самая долгая операция. На конфигурации с 2000+ объектами загрузка из файлов занимает 8-12 минут. И всё это время пользователи отключены, хотя загрузка конфигурации не требует монопольного доступа.
Ключевая идея: LoadConfigFromFiles до кика

Факт, который не все знают: LoadConfigFromFiles можно выполнять, пока пользователи работают. Эта команда загружает конфигурацию в хранилище конфигурации БД, но не применяет изменения к структуре данных. Пользователи продолжают работать со старой версией.
Монопольный режим нужен только для UpdateDBCfg — когда платформа изменяет структуру таблиц SQL Server. Эта операция занимает 1-3 минуты (зависит от объёма изменений в структуре данных).
Оптимизированный порядок:
- LoadConfigFromFiles — пользователи работают (8-12 минут, простоя нет)
- Остановить Apache — закрыть доступ через веб-клиент
- Отключить сеансы через rac.exe
- UpdateDBCfg — монопольное обновление (1-3 минуты)
- Запустить Apache — пользователи подключаются
Простой сократился с 20 минут до 3-5. Пользователи отключены только на время UpdateDBCfg + время кика сеансов (обычно 30-60 секунд).
Почему именно 8-12 минут? LoadConfigFromFiles выполняет сравнение каждого объекта метаданных из файлов с текущей конфигурацией в базе. Для конфигурации ERP с 2500+ объектами это тысячи файлов XML. Платформа парсит каждый файл, сравнивает хеши, при различии — загружает новую версию. Даже если изменился только один модуль — проверяются все объекты.
Можно ускорить LoadConfigFromFiles, если загружать не всю конфигурацию, а только изменённые файлы. Но это требует хранения состояния между деплоями и реализации diff на стороне пайплайна — мы не стали усложнять, поскольку LoadConfig не создаёт простоя.
Управление сеансами: почему rac, а не HTTP-сервис
Первая версия нашего пайплайна использовала HTTP-сервис внутри 1С для управления сеансами. POST /api/sessions/block — блокировка, POST /api/sessions/terminate — кик. Красиво, REST-like, всё через API.
Через неделю поймали deadlock. HTTP-сервис обрабатывается через сеанс 1С. Когда мы ставим блокировку базы через этот HTTP-сервис, планировщик заданий 1С не может создать новый сеанс для обработки следующего запроса — запроса на снятие блокировки. Замкнутый круг.
Решение — утилита rac.exe. Она входит в стандартную поставку платформы 1С и обращается напрямую к серверу RAS (Remote Administration Server) через порт 1545. Минуя веб-сервер, минуя планировщик заданий, минуя саму 1С.
#!/bin/bash
CLUSTER=$(rac cluster list | grep cluster | awk '{print $NF}')
IB=$(rac infobase summary list --cluster=$CLUSTER \
| grep -B1 "your_base" | grep infobase | awk '{print $NF}')
# Список активных сеансов
rac session list --cluster=$CLUSTER --infobase=$IB
# Блокировка новых подключений
rac infobase update --cluster=$CLUSTER --infobase=$IB \
--sessions-deny=on --denied-message="Обновление, подождите 3 минуты"
# Завершение существующих сеансов (кроме Конфигуратора)
rac session list --cluster=$CLUSTER --infobase=$IB \
| grep -v "Designer" | grep session-id | awk '{print $NF}' \
| while read SID; do
rac session terminate --cluster=$CLUSTER --session=$SID
done
# ... UpdateDBCfg ...
# Снятие блокировки
rac infobase update --cluster=$CLUSTER --infobase=$IB \
--sessions-deny=off --denied-message=""Мы проверяли: на конфигурации с 1800 объектами и 150 доработанными модулями LoadConfigFromFiles занимает 9 минут. UpdateDBCfg при добавлении 3 новых реквизитов — 1 минута 40 секунд. При изменении типа существующего реквизита (реструктуризация таблицы) — 4 минуты. Суммарный простой — от 2 до 5 минут в зависимости от характера изменений.
Динамическое обновление: UpdateDBCfg -Dynamic+
Начиная с платформы 8.3.15, появился параметр -Dynamic+ для UpdateDBCfg. Он позволяет обновить структуру БД без полной блокировки — если изменения не затрагивают критичные структуры (добавление новых реквизитов, новых объектов).
Ограничения: динамическое обновление не работает при удалении реквизитов, изменении типов, реструктуризации таблиц. В этих случаях платформа автоматически переключается на монопольный режим.
# Попытка динамического обновления
1cv8 DESIGNER /S "server\base" /UpdateDBCfg -Dynamic+ \
/Out update.log /DisableStartupDialogsНа практике динамическое обновление срабатывает примерно в 60% случаев — когда добавляются новые реквизиты, формы, модули без изменения структуры существующих таблиц. В остальных 40% — нужна классическая монопольная схема.
Наш пайплайн сначала пытается динамическое обновление. Если не получилось — падает на ветку с полным обновлением через кик сеансов.
Остановка Apache перед обновлением
Зачем останавливать Apache, если мы и так блокируем сеансы через rac? Потому что веб-клиент. Пользователь открыл 1С в браузере, вкладка висит, соединение keep-alive. При блокировке сеансов через rac существующее HTTP-соединение не обрывается мгновенно. Пользователь может попытаться выполнить действие — и получить непонятную ошибку.
Остановка Apache — чистый разрыв всех HTTP-соединений. Пользователь видит «Сервер недоступен» (понятно, что что-то происходит) вместо «Ошибка сеанса 1С» (непонятно и страшно).
# Остановка перед деплоем
sudo systemctl stop apache2 # или httpd
# ... LoadConfig уже выполнен ...
# ... rac terminate sessions ...
# ... UpdateDBCfg ...
# Запуск после деплоя
sudo systemctl start apache2GitHub Actions: полный пайплайн
Наш продакшен-пайплайн работает через GitHub Actions. Коммит в main → запускается workflow → обновляется база. Примерная структура:
# .github/workflows/deploy-1c.yml (упрощённо)
jobs:
deploy:
runs-on: [self-hosted, 1c-server]
concurrency:
group: deploy-1c
cancel-in-progress: false
steps:
- uses: actions/checkout@v4
- name: Load config (users online)
run: |
1cv8 DESIGNER /S "$SERVER\$BASE" \
/LoadConfigFromFiles ./src/cf \
/Out load.log /DisableStartupDialogs
- name: Stop Apache
run: sudo systemctl stop apache2
- name: Terminate sessions
run: ./scripts/terminate-sessions.sh
- name: Update DB
run: |
1cv8 DESIGNER /S "$SERVER\$BASE" \
/UpdateDBCfg /Out update.log /DisableStartupDialogs
- name: Start Apache
run: sudo systemctl start apache2
- name: Unblock sessions
run: ./scripts/unblock-sessions.shВажный момент — concurrency group. Если два коммита пришли подряд, второй деплой ждёт завершения первого, а не запускается параллельно. Без этого два конкурентных UpdateDBCfg — гарантированная проблема.

Мониторинг деплоя
Каждый деплой логируется. LoadConfigFromFiles и UpdateDBCfg пишут результат в файлы load.log и update.log соответственно. Пайплайн после каждого шага проверяет exit code и содержимое лога на наличие слова «Ошибка» или «Error».
Кроме логов, мы записываем метрики каждого деплоя: время начала, время завершения, длительность простоя, количество отключённых пользователей, размер обновления (количество изменённых объектов). За полгода накопилась статистика, которая помогает планировать окна обслуживания и прогнозировать время простоя для разных типов обновлений.
Если деплой завершился с ошибкой, пайплайн автоматически запускает Apache и снимает блокировку сеансов — чтобы пользователи могли продолжить работу со старой версией конфигурации, пока разработчики разбираются с проблемой. Без этого при ошибке деплоя пользователи оставались заблокированы до ручного вмешательства.
Откат: что делать, если обновление сломало базу
UpdateDBCfg — необратимая операция. После обновления структуры базы данных откатить конфигурацию назад нельзя. Точнее, можно загрузить старую версию конфигурации, но если UpdateDBCfg удалил реквизиты или изменил типы — данные потеряны.
Поэтому перед каждым деплоем — бэкап. В нашем пайплайне бэкап выполняется автоматически перед LoadConfigFromFiles:
- name: Backup before deploy
run: |
sqlcmd -S localhost -Q "BACKUP DATABASE [$DB_NAME] TO DISK='D:\Backups\pre-deploy-$(date +%Y%m%d-%H%M).bak' WITH COMPRESSION, CHECKSUM"Бэкап с COMPRESSION на базе 50 ГБ занимает 3-5 минут. Это страховка, которая себя окупает при первой же проблеме. Мы храним пре-деплойные бэкапы 3 дня — достаточно, чтобы обнаружить проблему и откатить.
Если UpdateDBCfg упал с ошибкой (а такое бывает — конфликт блокировок, нехватка места, ошибка реструктуризации), база остаётся в промежуточном состоянии. Конфигурация загружена, но не применена. В этом случае нужно:
- Проанализировать ошибку в update.log
- Если ошибка исправима (блокировки) — повторить UpdateDBCfg
- Если ошибка в конфигурации — загрузить старую версию и повторить UpdateDBCfg
- В крайнем случае — восстановить из бэкапа
Уведомления пользователей
Пользователи должны знать, что обновление идёт. Ничего хуже, чем молча отключить людей в середине ввода документа.
Мы используем два уровня уведомлений:
За 10 минут до деплоя: сообщение через штатный механизм 1С (оповещения пользователей). Текст: «Через 10 минут будет обновление. Сохраните работу». Это делается через rac, который отправляет сообщение всем активным сеансам:
rac infobase update --cluster=$CLUSTER --infobase=$IB --sessions-deny=on --denied-from="$(date -d '+10 min' '+%Y-%m-%dT%H:%M:%S')" --denied-message="Обновление системы. Сохраните данные."Ключевой момент: параметр --denied-from устанавливает отложенную блокировку. Новые подключения запрещаются через 10 минут, а текущие пользователи видят предупреждение в интерфейсе 1С.
В момент обновления: сообщение в Telegram-канал команды. Автоматически из пайплайна: «Обновление базы начато, ожидаемое время простоя — 3-5 минут».
После завершения — второе сообщение: «Обновление завершено, база доступна». Это помогает и пользователям, и администраторам видеть историю деплоев.
Фильтрация сеансов при кике
Не все сеансы нужно завершать. Сеанс Конфигуратора (Designer) — тот самый, через который выполняется UpdateDBCfg. Если его кикнуть — обновление прервётся.
Фильтруем по типу приложения:
# Завершить все сеансы, кроме Designer и BackgroundJob
rac session list --cluster=$CLUSTER --infobase=$IB | grep -E "session-id|app-id" | paste - - | grep -v "Designer" | grep -v "BackgroundJob" | awk '{print $2}' | while read SID; do
rac session terminate --cluster=$CLUSTER --session=$SID
doneBackgroundJob — фоновые задания. Их тоже лучше не кикать грубо — дать завершиться штатно. Для этого сначала ставим блокировку регламентных заданий (через rac infobase update --scheduled-jobs-deny=on), ждём 30 секунд, затем кикаем оставшиеся.
Итого
Три ключевых решения, которые сократили простой с 20 до 3-5 минут:
- LoadConfigFromFiles до отключения пользователей — самая долгая операция выполняется в фоне
- rac.exe вместо HTTP-сервиса — управление сеансами без deadlock, через RAS напрямую
- Остановка Apache — чистый разрыв HTTP-соединений, понятное поведение для пользователей
Это не rocket science. Просто правильный порядок операций и понимание того, какие из них требуют монополии, а какие — нет. Большинство скриптов обновления, которые мы видели у клиентов, выполняют всё подряд в монопольном режиме. Достаточно переставить LoadConfigFromFiles — и простой сокращается в 4-5 раз.