Есть ошибки в запросах 1С, которые видно сразу: запрос в цикле, соединение без условия, обращение к виртуальной таблице без параметров. Их ловит даже начинающий разработчик. Но есть другая категория — антипаттерны, которые выглядят нормально, проходят код-ревью и годами живут в продакшене. Пока база маленькая — всё работает. Когда данных становится много — начинаются тормоза.
Четыре паттерна ниже мы собрали из реальных проектов. Каждый — с замерами до и после. Ни один из них не описан в стандартной документации 1С как «антипаттерн».
1. УПОРЯДОЧИТЬ в запросе с ПОМЕСТИТЬ

Запрос помещает данные во временную таблицу для дальнейшего использования. Разработчик по привычке добавляет УПОРЯДОЧИТЬ ПО — чтобы «данные лежали по порядку». Логично? На первый взгляд — да. На деле — бессмысленная нагрузка.
Временная таблица — это не результат запроса, который увидит пользователь. Это промежуточное хранилище. SQL Server не гарантирует порядок строк во временной таблице, даже если вы его указали. При следующем SELECT из этой таблицы порядок может быть любым — если только вы не укажете ORDER BY снова.
Что происходит внутри: SQL Server выполняет сортировку (Sort operator в плане запроса), выделяет память под буфер сортировки, при нехватке — сбрасывает на диск (tempdb spill). На таблице в 500 000 строк это стабильно добавляет 2-3 секунды. Просто так. Впустую.
// Было — сортировка ради сортировки
ВЫБРАТЬ
Товар.Ссылка КАК Товар,
Товар.Наименование
ПОМЕСТИТЬ ВрТовары
ИЗ Справочник.Номенклатура КАК Товар
УПОРЯДОЧИТЬ ПО Товар.Наименование // лишнее
// Стало — убрали УПОРЯДОЧИТЬ
ВЫБРАТЬ
Товар.Ссылка КАК Товар,
Товар.Наименование
ПОМЕСТИТЬ ВрТовары
ИЗ Справочник.Номенклатура КАК ТоварЭтот антипаттерн коварен тем, что в конфигураторе подсветки ошибки нет. Проверка синтаксиса проходит. Даже если включить предупреждения — конструктор запросов не отмечает УПОРЯДОЧИТЬ в промежуточном запросе как проблему. Единственный способ обнаружить — анализ плана запроса в SQL Server Management Studio или через ТЖ с событием SDBL.
Частный случай — УПОРЯДОЧИТЬ ПО внутри ОБЪЕДИНИТЬ ВСЕХ. Здесь ситуация ещё хуже: SQL Server вынужден отсортировать каждую ветку ОБЪЕДИНЕНИЯ отдельно, а потом результат всё равно перемешивается. Двойная бессмысленная работа.
В проекте для ресторанной сети мы нашли этот паттерн в трёх ключевых отчётах. Убрали УПОРЯДОЧИТЬ из промежуточных запросов — общее время формирования сократилось на 15-20%.
2. Подзапрос в ВЫБОР (CASE WHEN)
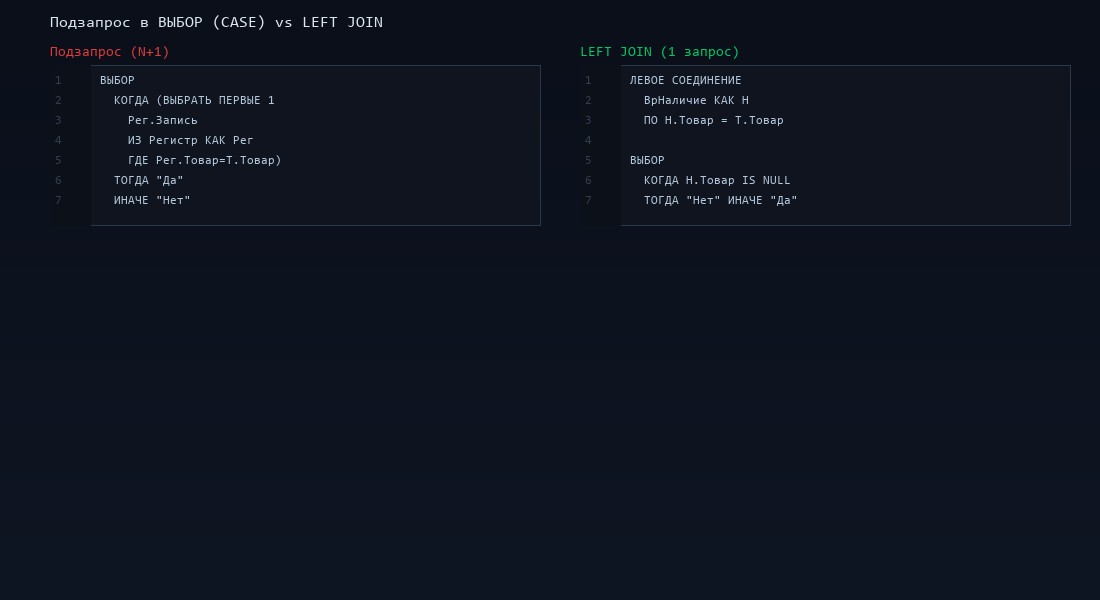
Задача: для каждого товара определить, есть ли он в наличии на складе. Разработчик пишет подзапрос внутри конструкции ВЫБОР КОГДА:
ВЫБРАТЬ
Т.Ссылка,
Т.Наименование,
ВЫБОР КОГДА (ВЫБРАТЬ ПЕРВЫЕ 1 1
ИЗ РегистрНакопления.ТоварыНаСкладах.Остатки КАК Ост
ГДЕ Ост.Номенклатура = Т.Ссылка И Ост.КоличествоОстаток > 0)
НЕ ЕСТЬ NULL
ТОГДА "В наличии"
ИНАЧЕ "Нет"
КОНЕЦ КАК Наличие
ИЗ Справочник.Номенклатура КАК ТВыглядит компактно. Работает на 100 товарах. На 10 000 товаров — превращается в 10 000 подзапросов. SQL Server выполняет correlated subquery для каждой строки основного запроса. По сути — запрос в цикле, замаскированный под один запрос.
Решение: вынести проверку в LEFT JOIN через временную таблицу.
// Шаг 1: подготовить данные о наличии
ВЫБРАТЬ РАЗЛИЧНЫЕ
Ост.Номенклатура КАК Товар
ПОМЕСТИТЬ ВрВНаличии
ИЗ РегистрНакопления.ТоварыНаСкладах.Остатки КАК Ост
ГДЕ Ост.КоличествоОстаток > 0
;
// Шаг 2: использовать LEFT JOIN
ВЫБРАТЬ
Т.Ссылка,
Т.Наименование,
ВЫБОР КОГДА Н.Товар ЕСТЬ NULL ТОГДА "Нет" ИНАЧЕ "В наличии" КОНЕЦ
ИЗ Справочник.Номенклатура КАК Т
ЛЕВОЕ СОЕДИНЕНИЕ ВрВНаличии КАК Н
ПО Н.Товар = Т.СсылкаНа практике подзапрос в ВЫБОР часто возникает, когда разработчик дорабатывает существующий запрос «по-быстрому»: нужно добавить колонку «есть/нет», самый простой способ — подзапрос. Рефакторинг через временную таблицу занимает больше времени, но окупается на объёмах.
Замер на реальной базе (12 000 номенклатурных позиций): подзапрос в ВЫБОР — 24 секунды, LEFT JOIN через временную таблицу — 3 секунды. Ускорение в 8 раз.
3. ИНДЕКСИРОВАТЬ ПО полю составного типа
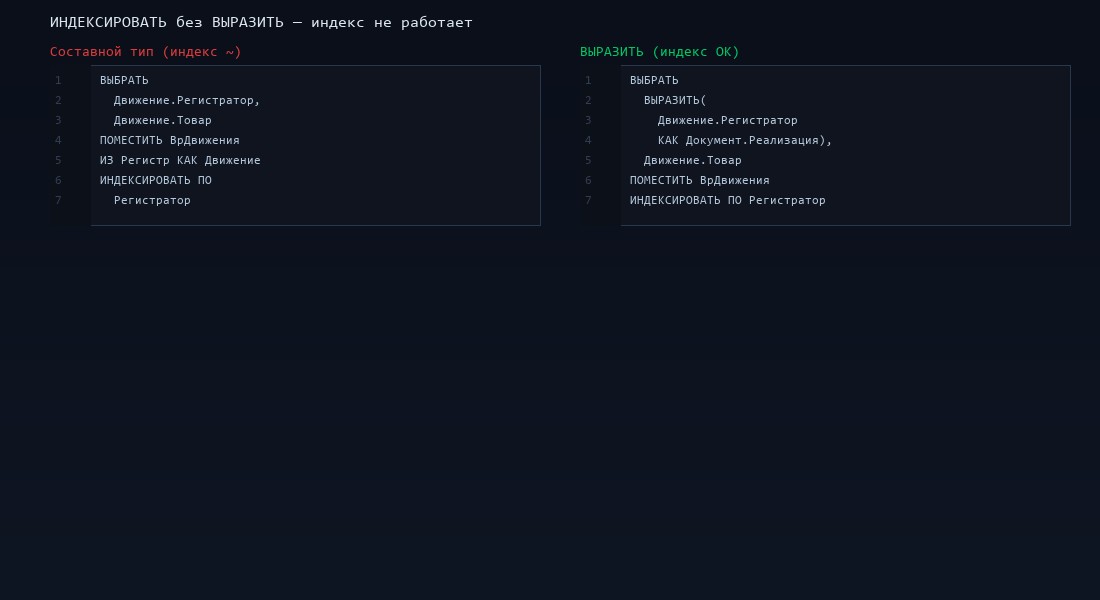
Временная таблица с полем составного типа. Разработчик добавляет ИНДЕКСИРОВАТЬ ПО — и ожидает, что при соединении этот индекс ускорит запрос. На практике эффект нулевой или даже отрицательный.
Почему: составной тип в 1С хранится в нескольких колонках SQL (одна для каждого типа-участника + колонка дискриминатора). Индекс по такому «полю» получается составной — по всем этим колонкам. SQL Server не может его эффективно использовать для поиска по конкретному типу.
Решение: ВЫРАЗИТЬ к конкретному типу перед индексированием.
// Было — индекс не работает
ВЫБРАТЬ
Движение.Регистратор КАК Документ,
Движение.Товар
ПОМЕСТИТЬ ВрДвижения
ИЗ РегистрНакопления.Продажи КАК Движение
ИНДЕКСИРОВАТЬ ПО Документ // составной тип — бесполезно
;
// Стало — индекс работает
ВЫБРАТЬ
ВЫРАЗИТЬ(Движение.Регистратор КАК Документ.РеализацияТоваров) КАК Документ,
Движение.Товар
ПОМЕСТИТЬ ВрДвижения
ИЗ РегистрНакопления.Продажи КАК Движение
ГДЕ Движение.Регистратор ССЫЛКА Документ.РеализацияТоваров
ИНДЕКСИРОВАТЬ ПО Документ // один тип — индекс OKЕщё хуже ситуация, когда поле составного типа не типизировано и при этом используется в ИНДЕКСИРОВАТЬ ПО. В некоторых версиях платформы это вызывает ошибку SQL Server. В других — молча создаёт бесполезный индекс, расходуя ресурсы TempDB.
Важно: речь не о том, что составные типы в 1С — это плохо. Составные типы решают задачу полиморфизма, и без них не обойтись. Проблема возникает именно при индексировании — когда разработчик ожидает, что индекс ускорит запрос, а SQL Server физически не может использовать индекс по нескольким колонкам для поиска по одной из них. Добавление ВЫРАЗИТЬ — это не хак, а правильный способ сообщить оптимизатору, какой тип нас интересует.
На практике мы чаще всего встречаем этот антипаттерн в отчётах, которые собирают данные из регистров накопления: поле Регистратор всегда составного типа (все типы документов, которые делают движения). Без ВЫРАЗИТЬ индекс по Регистратору во временной таблице — мёртвый груз.
4. Нетипизированная временная таблица с ИНДЕКСИРОВАТЬ
Менее очевидный, но родственный паттерн. Результат запроса помещается во временную таблицу, и поле получает тип «Неопределено» — например, при ОБЪЕДИНЕНИИ разнотипных данных или при использовании NULL без ВЫРАЗИТЬ.
// Проблема — поле МаксДата нетипизировано
ВЫБРАТЬ
Товар,
МАКСИМУМ(Дата) КАК МаксДата
ПОМЕСТИТЬ ВрПоследние
ИЗ ВрВсеДвижения
СГРУППИРОВАТЬ ПО Товар
ИНДЕКСИРОВАТЬ ПО МаксДата // тип неизвестен — ошибка или деградацияАгрегатные функции (МАКСИМУМ, МИНИМУМ) над полями составного типа возвращают результат составного типа. Индекс по такому полю — лотерея. В лучшем случае он просто не используется. В худшем — SQL Server получает ошибку при создании индекса, и весь пакетный запрос падает.
Фикс: добавить ВЫРАЗИТЬ к агрегатной функции.
ВЫБРАТЬ
Товар,
МАКСИМУМ(ВЫРАЗИТЬ(Дата КАК ДАТА)) КАК МаксДата
ПОМЕСТИТЬ ВрПоследние
ИЗ ВрВсеДвижения
СГРУППИРОВАТЬ ПО Товар
ИНДЕКСИРОВАТЬ ПО МаксДата // тип ДАТА — индекс работаетКак искать антипаттерны в существующем коде
Ручной аудит — надёжно, но долго. В конфигурации ERP — тысячи запросов. Не будешь же каждый открывать. Есть способы быстрее.
Query Store (SQL Server 2016+). Отсортируйте запросы по суммарному времени выполнения или по количеству логических чтений. Топ-20 запросов — это 80% нагрузки. Откройте план выполнения для каждого. Ищите:
- Sort operator, который не связан с ORDER BY в финальном SELECT — это скорее всего УПОРЯДОЧИТЬ в промежуточном запросе
- Nested Loops с корреляцией (correlated subquery) — подзапрос в ВЫБОР
- Index Scan вместо Index Seek на временной таблице — неработающий индекс из-за составного типа
- Table Spool (Lazy Spool) — часто следствие нетипизированных временных таблиц
Технологический журнал с событием SDBL. Включите логирование запросов с длительностью более 3 секунд. За день соберёте полную картину тяжёлых запросов. Контекст события покажет, какой объект метаданных и какая строка кода выполняет проблемный запрос.
<log location="C:C_Logs" history="2">
<event>
<eq property="name" value="SDBL"/>
<ge property="Durationus" value="3000000"/>
</event>
<property name="all"/>
</log>Глобальный поиск по конфигурации. В конфигураторе: Ctrl+Shift+F → искать «УПОРЯДОЧИТЬ» рядом с «ПОМЕСТИТЬ». Или «ВЫБРАТЬ ПЕРВЫЕ 1» внутри конструкции «ВЫБОР КОГДА». Не автоматизируешь полностью, но топ-кандидатов находишь быстро.
Когда антипаттерны допустимы
Не всегда «неправильный» код нужно переписывать. Контекст решает.
УПОРЯДОЧИТЬ в ПОМЕСТИТЬ допустим, если временная таблица используется ровно один раз и SQL Server всё равно не делает Sort (оптимизатор может проигнорировать ORDER BY при INSERT INTO). Проверяйте по плану запроса: если Sort operator отсутствует — антипаттерн безвреден.
Подзапрос в ВЫБОР допустим на маленьких наборах данных (до 100-200 строк). Накладные расходы на создание временной таблицы и LEFT JOIN могут перевесить «стоимость» 200 подзапросов. Но если набор может вырасти — лучше сразу написать правильно.
Индекс по составному типу иногда работает — если в таблице всего 2-3 типа и все они присутствуют. SQL Server может построить приемлемый план. Но это исключение, а не правило.
Правило большого пальца: если запрос выполняется менее 0.5 секунды — оставьте как есть. Оптимизация запроса, который работает 100 миллисекунд, не стоит затраченного времени. Фокусируйтесь на запросах, которые реально мешают пользователям.
Суммарный эффект
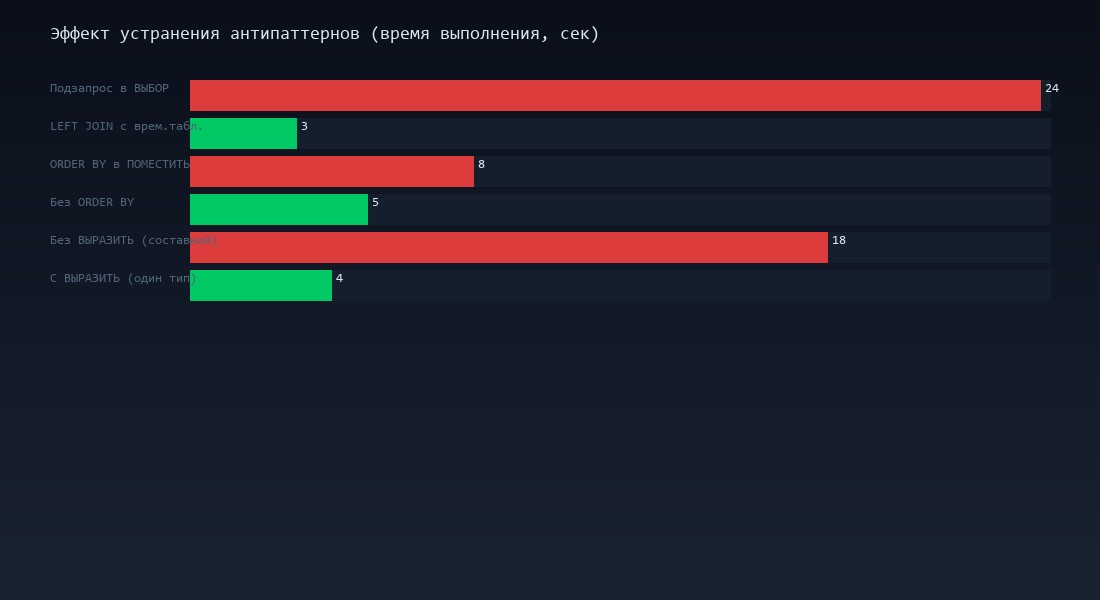
Каждый из этих антипаттернов по отдельности добавляет секунды. В комбинации — минуты. Мы встречали отчёты, где все четыре паттерна присутствовали одновременно. Время формирования — 4 минуты. После исправления — 35 секунд.
Коварность этих ошибок в том, что они не видны в коде без анализа плана запроса. Запрос выглядит правильным, возвращает корректный результат, проходит тестирование. Проблема проявляется только под нагрузкой, на реальных объёмах данных.
Что помогает их находить:
- Планы запросов. Sort operator при ПОМЕСТИТЬ — почти всегда лишний. Nested Loops с подзапросом — сигнал проблемы. Index Scan вместо Index Seek — индекс не работает
- Замеры времени. Технологический журнал с событием SDBL покажет реальное время каждого запроса
- Query Store (если SQL Server) — топ запросов по длительности и потреблению ресурсов, история изменений планов
Проверьте свои ключевые отчёты и обработки. Если в них есть хотя бы один из этих паттернов — вы найдёте резерв для ускорения.