Звонок от клиента: «1С не открывается, уже полчаса». Смотрим — сервер 1С упал сорок минут назад. Никто не заметил, потому что мониторинга нет. Есть Zabbix, но он следит за CPU и диском. А то, что процесс rphost перестал отвечать на HTTP-запросы — не видит.
После третьего такого звонка мы настроили нормальный мониторинг. Не универсальный, а конкретно для 1С. Расскажу, как.
Стек: почему именно Prometheus
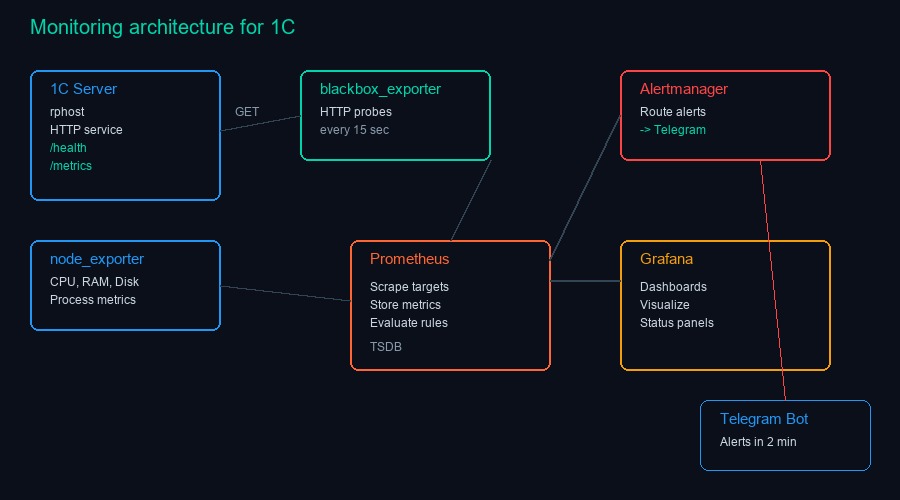
Prometheus + Grafana + Alertmanager. Стек стандартный для DevOps-мира, но в мире 1С встречается редко. Обычно ставят Zabbix или PRTG, иногда обходятся встроенным мониторингом в ЦКК (Центр контроля качества). Мы выбрали Prometheus по трём причинам.
Первая — pull-модель. Prometheus сам ходит за метриками. Не нужно настраивать агентов на каждом сервере 1С. Достаточно эндпоинта, который отдаёт метрики в текстовом формате.
Вторая — blackbox_exporter. Внешний модуль, который проверяет доступность HTTP-эндпоинтов. Для 1С это идеально: HTTP-сервисы встроены в платформу. Публикуем простой сервис-заглушку, blackbox_exporter делает запрос каждые 15 секунд. Если ответа нет — алерт.
Третья — Grafana. Дашборды, которые можно собрать за час и которые реально используют. Не абстрактные графики нагрузки, а конкретные метрики: время отклика HTTP-сервиса 1С, количество сеансов, статус фоновых заданий.
Что мониторим и как
Уровень 1: жив или мёртв. Blackbox_exporter проверяет HTTP-сервис, опубликованный в информационной базе. Сервис максимально простой — возвращает HTTP 200 и текст «OK». Если сервис отвечает — значит, вся цепочка работает: Apache/IIS, сервер 1С, rphost, информационная база.
Важный нюанс с кодами ответа. Если HTTP-сервис принимает только POST, а blackbox_exporter отправляет GET — вернётся HTTP 405 Method Not Allowed. Сервис жив, но probe_success покажет 0. По умолчанию blackbox_exporter считает успешными только коды 2xx.
Решение: отдельный модуль в конфиге blackbox_exporter с явным списком допустимых кодов. Мы включаем все, кроме 5xx. Код 405 — сервис жив, просто метод не тот. Код 401 — сервис жив, просто нужна авторизация. Пятисотые — реальная проблема.
Уровень 2: метрики производительности. Здесь нужен HTTP-сервис посложнее. Создаём эндпоинт /metrics, который отдаёт данные в формате Prometheus:
Количество активных сеансов (запрос к регистру сведений или через COM-соединение к серверу администрирования). Количество фоновых заданий в статусе «Выполняется» и «Завершено с ошибкой». Время последнего успешного выполнения регламентного задания обмена данными. Размер очереди заданий.
Уровень 3: инфраструктура. Node_exporter (или windows_exporter) на сервере 1С. CPU, RAM, диск, сеть. Но с фокусом на процессы 1С: потребление памяти rphost, ragent, rmngr. Если rphost съел 8 ГБ — скоро будет перезапуск.

Настройка blackbox_exporter: конкретный конфиг
Конфиг blackbox_exporter состоит из модулей. Каждый модуль — это шаблон проверки. Для 1С нужны минимум два.
Первый модуль — http_1c_alive. Проверяет, что HTTP-сервис 1С отвечает. Допустимые коды: всё кроме 5xx. Таймаут: 10 секунд. Если 1С не ответила за 10 секунд на простейший запрос — что-то не так.
Второй модуль — http_1c_strict. Проверяет конкретный эндпоинт с конкретным ожидаемым ответом. Допустимые коды: только 200. Дополнительно проверяет, что в теле ответа содержится ожидаемая строка — например, «healthy». Это для критичных сервисов, где важна не только доступность, но и корректность.
В prometheus.yml добавляем job с relabeling — стандартная конструкция для blackbox. Targets — список URL-ов ваших HTTP-сервисов 1С. Каждый URL — отдельная информационная база.
Интервал опроса: 15 секунд для alive-проверки, 60 секунд для метрик. Чаще не нужно — создаёте лишнюю нагрузку на сервер 1С.
Алерты: что и когда
Три обязательных алерта:
1С не отвечает более 2 минут. Условие: probe_success == 0 в течение 2 минут (for: 2m). Не реагируем на единичный сбой — бывает, что rphost перезапускается штатно. Два minutes — значит, проблема реальная. Канал: Telegram. Приоритет: critical.
Время отклика выше 5 секунд. Условие: probe_duration_seconds > 5 в течение 5 минут. Сервис отвечает, но медленно. Обычно это означает, что сервер 1С перегружен или база заблокирована фоновым заданием. Канал: Telegram. Приоритет: warning.
Фоновое задание завершилось с ошибкой. Условие: метрика background_jobs_failed > 0. Канал: Telegram. Приоритет: warning. Этот алерт экономит часы диагностики — вместо «что-то данные в отчёте странные» вы видите «задание обмена с сайтом упало в 03:15 с ошибкой таймаута».
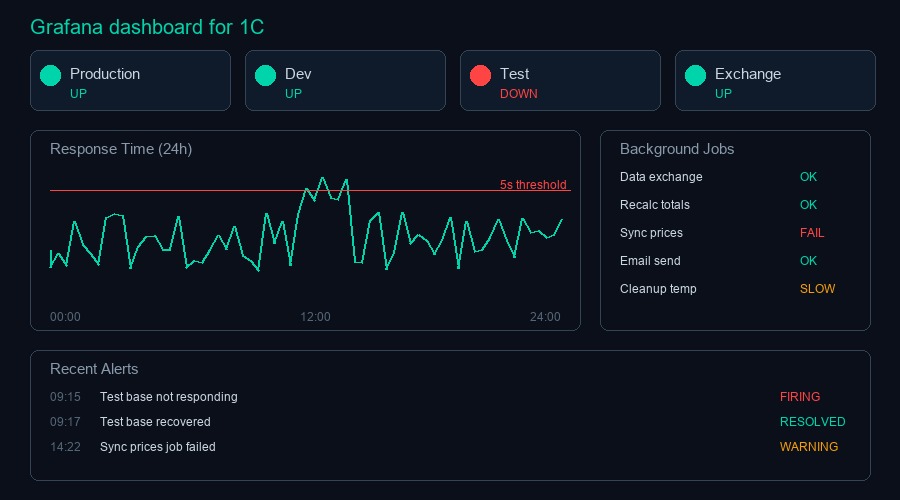
Grafana: дашборд для 1С
Минимальный дашборд, который имеет смысл:
Верхняя строка: статусы всех баз. Зелёный — работает, красный — не отвечает. Stat panel с порогами: 1 = зелёный, 0 = красный. Открываешь дашборд — за секунду видишь, всё ли живо.
Графики: время отклика каждого HTTP-сервиса за последние 24 часа. Видно паттерны: ночью быстро, днём медленнее, в 14:00 пик — закрытие кассовых смен.
Таблица: фоновые задания, последний статус, время выполнения, ошибки. Сортировка по ошибкам — проблемные наверху.
Не делайте дашборд на 40 панелей. Три-пять панелей, которые реально смотрят каждый день. Остальное добавится, когда появится конкретная потребность.
Результат
После настройки мониторинга мы перестали узнавать о проблемах от пользователей. Telegram-бот присылает алерт — и мы уже разбираемся, пока бухгалтер ещё не заметила.
Среднее время реакции сократилось с 30-40 минут (пока позвонят, пока объяснят) до 2-3 минут (алерт пришёл — подключились). Для бизнеса это разница между «потеряли час работы» и «даже не заметили».
Настройка заняла два рабочих дня. Prometheus и Grafana — Docker-контейнеры, поднимаются за минуты. HTTP-сервис в 1С — двадцать строк кода. Blackbox_exporter — один конфиг-файл. Самое долгое — разобраться с алертами и каналами уведомлений.
Два дня работы, которые с тех пор экономят часы каждый месяц. И — что важнее — нервы.