Звонок от IT-директора крупной торговой компании. После обеда сервер 1С начинает тормозить. 200 пользователей работают в ERP. Утром всё быстро. К двум часам дня документы проводятся по 15 секунд. К четырём — по 40. Перезагрузка сервера помогает. На следующий день история повторяется.
Сервер мощный: 64 ГБ RAM, два Xeon по 12 ядер, SSD. SQL Server настроен грамотно. Код оптимизирован. Проблема оказалась в настройках кластера 1С — точнее, в их отсутствии. Все параметры стояли по умолчанию. Для 20 пользователей этого хватает. Для 200 — нет.
Что такое кластер серверов 1С и зачем его трогать
Кластер 1С — это не один процесс, а архитектура из трёх компонентов. ragent — агент сервера, точка входа. Он запускается как служба Windows, слушает порт 1540 и управляет всем остальным. Именно ragent принимает решение о запуске и остановке остальных процессов. Если ragent упал — кластер мёртв целиком.
rmngr — менеджер кластера. Отвечает за распределение сеансов, управление блокировками, запуск фоновых и регламентных заданий, а также за кэш метаданных. На каждый кластер — один менеджер. Rmngr сам по себе не выполняет пользовательский код, но координирует тех, кто выполняет.
rphost — рабочий процесс. Именно здесь выполняется код 1С: запросы к базе данных, проведения документов, формирование отчётов, обработка HTTP-сервисов. Каждый rphost — отдельный процесс операционной системы со своим адресным пространством. Это рабочая лошадка кластера. Все пользовательские операции проходят через rphost.
Когда пользователь открывает форму или проводит документ, его сеанс обслуживается одним из рабочих процессов. Если rphost один — все 200 пользователей толкаются в одном процессе. Один пул потоков, одна очередь на выполнение. Если рабочих процессов несколько — нагрузка распределяется между ними.
По умолчанию кластер запускает один rphost. Один процесс на весь сервер. При 20 пользователях это работает приемлемо. При 200 — процесс раздувается до десятков гигабайт, сборщик мусора начинает тратить секунды на каждую итерацию, потоки конкурируют за общие ресурсы, и всё замедляется нелинейно. Сервер с 24 ядрами фактически работает как одноядерный — потому что узкое место не в CPU, а в адресном пространстве единственного процесса.
Диагностируется это за минуту. Открываем диспетчер задач на сервере (или выполняем ps aux | grep rphost на Linux) и смотрим список процессов. В здоровой конфигурации вы увидите несколько rphost примерно одинакового размера — по 3-5 ГБ каждый. В проблемной — один rphost, который потребляет 25-30 ГБ, а остальные (если вообще есть) сидят почти пустыми на уровне 200-400 МБ. Дополнительно выполняем rac process list — в столбце memory-size видна картина в числах. Если единственный rphost показывает memory-size, растущий в течение дня и к вечеру приближающийся к объёму физической памяти сервера — диагноз подтверждён. Мы видели серверы, где один rphost занимал 48 ГБ из 64 доступных, вытесняя SQL Server в своп. Администратор был уверен, что «кластер настроен» — служба работала, пользователи подключались. Формально так и было. По факту — с параметрами по умолчанию кластер использовал 64-ядерный сервер как однопроцессную рабочую станцию.

Рабочие процессы: сколько нужно на самом деле
Стандартная рекомендация 1С — один рабочий процесс на каждые 4 физических ядра. На сервере с 24 ядрами — 6 рабочих процессов. Это отправная точка, не догма.
На практике формула сложнее. Вот что мы учитываем:
- Количество активных пользователей. Не подключённых, а реально работающих в моменте. 200 подключённых — это обычно 60-80 активных. На каждые 15-20 активных пользователей нужен один rphost.
- Характер нагрузки. Если пользователи работают с тяжёлыми документами (закрытие месяца, расчёт себестоимости) — процессов нужно больше. Один тяжёлый расчёт может загрузить rphost на минуты, блокируя остальных пользователей в этом процессе. Если в основном просматривают справочники — меньше.
- Объём памяти. Каждый rphost потребляет от 1 до 8 ГБ в зависимости от нагрузки. Планируйте 4-6 ГБ на процесс как среднее значение. На сервере с 64 ГБ при 6 процессах — 24-36 ГБ только на rphost. Остальное отдаётся SQL Server и ОС.
Больше процессов — не всегда лучше. Типичная ошибка: администратор ставит 20 рабочих процессов на сервере с 16 ядрами. Результат — контекстные переключения забивают процессор. Каждый rphost создаёт свои потоки, и операционная система тратит больше времени на переключение между ними, чем на полезную работу. В диспетчере задач CPU показывает 100%, но полезной работы выполняется меньше, чем при четырёх процессах. Если запустить perfmon и посмотреть счётчик Context Switches/sec, на таких серверах он зашкаливает за 100 000 — при норме 10 000-30 000 для нагруженного сервера 1С. Каждое переключение контекста — это сохранение и восстановление состояния потока, сброс кэшей процессора, потеря 5-10 микросекунд. При 100 000 переключений в секунду процессор теряет до 15-20% производительности только на переключениях.
Мы видели серверы, где уменьшение количества rphost с 12 до 4 ускорило систему вдвое. Администратор думал, что увеличивает производительность, а на деле создавал конкуренцию за ядра процессора.
Есть ещё один нюанс. Каждый rphost поддерживает собственный пул соединений с SQL Server. 12 рабочих процессов — 12 пулов. Каждый пул открывает несколько соединений. SQL Server видит не 200 пользовательских сеансов, а 200 сеансов 1С плюс десятки служебных соединений от рабочих процессов. При слишком большом количестве rphost SQL Server тратит ресурсы на управление этими соединениями.
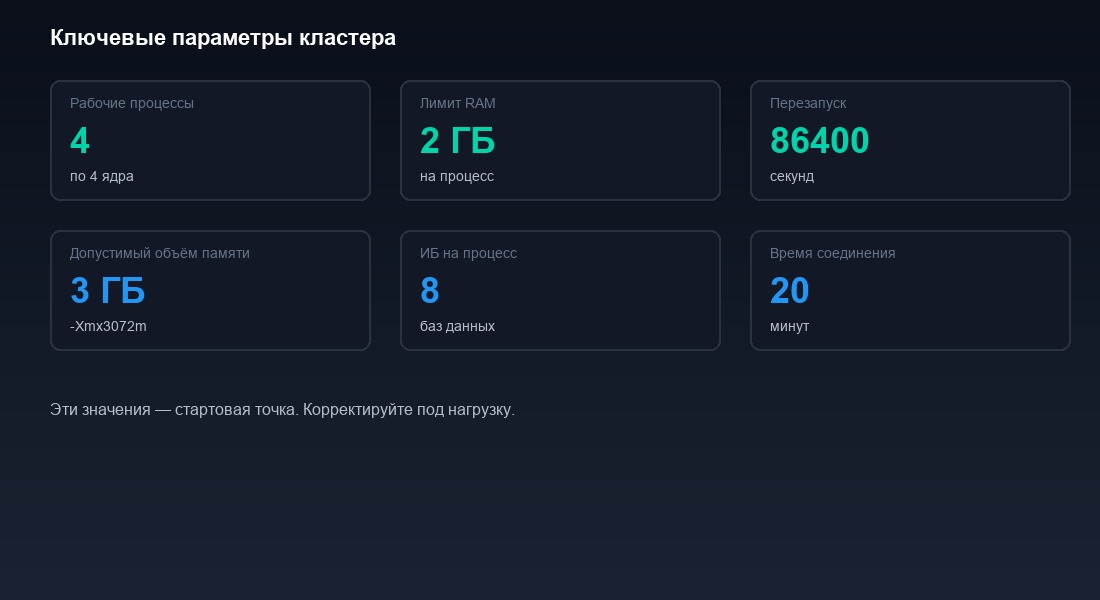
Для нашего случая с 200 пользователями и 24 ядрами мы выставили 6 рабочих процессов. Каждый обслуживает примерно 33 пользователя. Нагрузка распределилась равномерно, пиковое потребление памяти одним процессом снизилось с 28 ГБ до 5 ГБ.
Настройка количества рабочих процессов выполняется в консоли администрирования кластера или через утилиту rac:
rac process --cluster=<cluster-id> list --infobase=<ib-id> --cluster-admin=admin --cluster-pwd=pwdЧтобы добавить рабочие процессы, нужно изменить параметры рабочего сервера через rac server update, указав нужное количество процессов. Альтернатива — консоль администрирования кластера с графическим интерфейсом, но для автоматизации и документирования rac удобнее: команду можно сохранить в скрипт и воспроизвести на другом сервере.
Память: лимиты, которые спасают сервер
Без лимитов памяти rphost растёт бесконечно. Память выделяется, используется, объекты освобождаются — но операционной системе память не возвращается. Это не утечка в классическом смысле. Это фрагментация адресного пространства и особенность работы менеджера памяти 1С. Виртуальная машина 1С выделяет блоки памяти у ОС, но после освобождения объектов эти блоки остаются в пуле процесса. Со временем пул фрагментируется настолько, что выделение нового блока требует обращения к ОС, хотя свободная память в пуле формально есть.
На сервере с 64 ГБ один rphost может вырасти до 40-50 ГБ за рабочий день. Остальным процессам и SQL Server не останется ничего. Начинается своппинг. Своппинг на сервере 1С — это катастрофа. Даже SSD не спасает: задержки при обращении к свопу на порядки выше, чем при работе с RAM. Операция, которая из кэша выполняется за 1 мс, из свопа — 10-50 мс. Умножьте на тысячи операций в минуту.
Ключевые параметры, которые нужно выставить:
- Допустимый объём памяти (на один процесс). Рекомендуем 4-6 ГБ для средней нагрузки. Это мягкий порог: при его превышении кластер начнёт перенаправлять новые соединения на другие процессы. Текущие сеансы продолжат работать в этом rphost.
- Безопасный объём памяти. Выставляем на 20-30% больше допустимого. При превышении этого порога кластер принудительно перезапустит процесс, но дождётся завершения текущих вызовов. Пользователи не потеряют данные — их сеансы мигрируют на другой rphost.
- Максимальный объём памяти. Жёсткий потолок. При достижении — немедленный перезапуск без ожидания завершения вызовов. Ставим в 2 раза больше допустимого. Этот порог срабатывает только в аварийных ситуациях — когда процесс вышел из-под контроля.
На примере: допустимый — 4 ГБ, безопасный — 6 ГБ, максимальный — 8 ГБ. Процесс работает, накапливает данные. Дорос до 4 ГБ — новые сеансы пойдут на другой rphost. Дорос до 6 ГБ — после завершения текущих вызовов процесс перезапустится. Дорос до 8 ГБ по какой-то причине (зависший вызов, тяжёлая операция вроде закрытия месяца в ERP) — немедленный перезапуск.
Важный момент: лимиты задаются в килобайтах, а не в мегабайтах или гигабайтах. 4 ГБ = 4194304 КБ. Ошибка в единицах измерения — частая причина того, что лимиты «не работают». Администратор пишет 4096, думая о мегабайтах, а кластер интерпретирует это как 4096 КБ = 4 МБ. Процесс перезапускается мгновенно при старте.
Эти параметры задаются в свойствах рабочего сервера:
rac server update --cluster=<cluster-id> --server=<server-id> \
--safe-memory-limit=6291456 --memory-limit=8388608 \
--cluster-admin=admin --cluster-pwd=pwdБез этих лимитов сервер обречён на ежедневную деградацию. Это та самая ситуация из нашего кейса: к обеду всё тормозит, перезагрузка помогает, а завтра — снова.
Балансировка и перезапуск
Кластер 1С умеет балансировать нагрузку между рабочими процессами. Но делает он это по-своему, и не всегда оптимально.
По умолчанию используется балансировка по памяти. Новый сеанс направляется на процесс с наименьшим потреблением памяти. Звучит логично. Но на практике это приводит к эффекту «лавины»: свежий rphost после перезапуска потребляет минимум памяти, и балансировщик направляет на него все новые соединения. Через минуту свежий процесс становится самым нагруженным, а балансировщик уже отправил на него 80% пользователей. Остальные rphost простаивают.
Рекомендуем использовать балансировку по производительности. Кластер измеряет фактическое время отклика каждого rphost и направляет новые сеансы на самый быстрый. Этот режим объективнее отражает реальную нагрузку. Если rphost перегружен — его время отклика растёт, и новые сеансы автоматически уходят на более свободные процессы.
Плановые перезапуски — обязательная практика. Даже с лимитами памяти рабочие процессы накапливают фрагментацию. Плановый перезапуск раз в сутки в нерабочее время (например, в 3:00) решает проблему. Настраивается через параметр «Интервал перезапуска» в свойствах рабочего сервера. Указывается в секундах: 86400 — раз в сутки.
Перезапуск происходит мягко: кластер прекращает направлять новые сеансы на процесс, ждёт завершения текущих вызовов, останавливает процесс и запускает новый. Пользователи, работавшие с этим rphost, автоматически переключаются на другой процесс. Если всё настроено правильно — пользователи даже не заметят перезапуска.
Стоит учесть порядок перезапуска. Если все 6 рабочих процессов запустились одновременно и интервал перезапуска одинаковый — они перезапустятся одновременно. В 3:00 ночи кластер попытается перезапустить все rphost разом. Результат — кратковременная недоступность для ночных регламентных заданий и фоновых обменов. Решение: запускать рабочие процессы с разницей в несколько минут, чтобы интервалы перезапуска не совпадали. Или использовать разные значения интервала для разных процессов.
Тайм-аут отключения. Параметр определяет, сколько кластер ждёт завершения вызовов при перезапуске процесса. По умолчанию — бесконечно. Это значит, что один зависший вызов блокирует перезапуск навсегда. Процесс, который должен был перезапуститься в 3:00, продолжает работать до утра с раздутой памятью. Ставим 300 секунд (5 минут). Если за 5 минут вызов не завершился — процесс завершается принудительно. Пользователь с зависшим сеансом получит ошибку, но остальные 30 пользователей этого rphost продолжат работать на свежем процессе.
Отключение устаревших сеансов. Ещё один параметр, который часто игнорируют: тайм-аут неактивного сеанса. По умолчанию сеанс живёт бесконечно, пока пользователь не закроет 1С. На практике это означает, что сотрудник ушёл домой, не закрыв программу, — его сеанс продолжает занимать память rphost, удерживать соединение с SQL Server и учитываться при балансировке. Утром на сервере висит 50 «мёртвых» сеансов, которые занимают 2-3 ГБ суммарно. Рекомендуем выставить тайм-аут бездействия в 1200-1800 секунд (20-30 минут). Если пользователь не выполнял ни одного серверного вызова в течение этого времени, сеанс завершается. При следующем действии пользователь переподключится автоматически — для него это выглядит как короткая пауза. Параметр задаётся через rac session или в свойствах информационной базы в консоли кластера. В сочетании с плановыми перезапусками это гарантирует, что rphost не накапливает балласт из простаивающих сеансов.
Что проверить первым делом
Вот конкретные команды для диагностики текущей конфигурации кластера. Всё через rac — утилиту командной строки, которая идёт в поставке платформы 1С. Rac подключается к ragent по порту 1545 (по умолчанию) и позволяет просматривать и изменять параметры кластера без графического интерфейса.
Получить ID кластера:
rac cluster listВ ответе будет UUID кластера и его основные параметры. UUID понадобится для всех последующих команд.
Посмотреть рабочие процессы и их состояние:
rac process --cluster=<cluster-id> listВ выводе обратите внимание на поля memory-size (текущее потребление памяти в килобайтах), connections (количество соединений), is-enable (активен ли процесс), running (работает ли). Если memory-size у одного процесса в разы больше остальных — балансировка работает некорректно. Если is-enable = no, а running = yes — процесс заблокирован и ожидает завершения вызовов для перезапуска.
Посмотреть параметры рабочего сервера:
rac server --cluster=<cluster-id> listЗдесь видны лимиты памяти, интервал перезапуска, количество процессов и другие параметры. Если safe-call-memory-limit и safe-memory-limit стоят в 0 — лимиты не заданы. Это первое, что нужно исправить.
Посмотреть активные сеансы:
rac session --cluster=<cluster-id> list --infobase=<ib-id>Поле duration-current покажет длительность текущего вызова в миллисекундах. Если видите сеансы с вызовами по 600000+ мс (10 минут) — это зависшие операции, которые нужно разбирать отдельно. Поле process покажет UUID рабочего процесса, в котором работает сеанс — так можно определить, какой rphost перегружен.
Получить список соединений конкретного рабочего процесса:
rac connection --cluster=<cluster-id> --process=<process-id> listЭта команда покажет все соединения конкретного rphost. Полезно для понимания, какие базы и какие пользователи нагружают конкретный процесс.
Чек-лист для быстрой проверки:
- Рабочих процессов больше одного? Формула: 1 rphost на 4 ядра.
- Лимиты памяти выставлены? Допустимый — 4-6 ГБ, безопасный — 6-8 ГБ, максимальный — 8-12 ГБ (в килобайтах!).
- Интервал перезапуска указан? 86400 секунд — раз в сутки.
- Тайм-аут отключения не бесконечный? 300 секунд — разумный предел.
- Балансировка по производительности, а не по памяти?
- Каждый rphost потребляет не более допустимого лимита в пике?
- Время перезапуска разнесено, чтобы процессы не перезапускались одновременно?
- Количество соединений распределено равномерно между процессами?
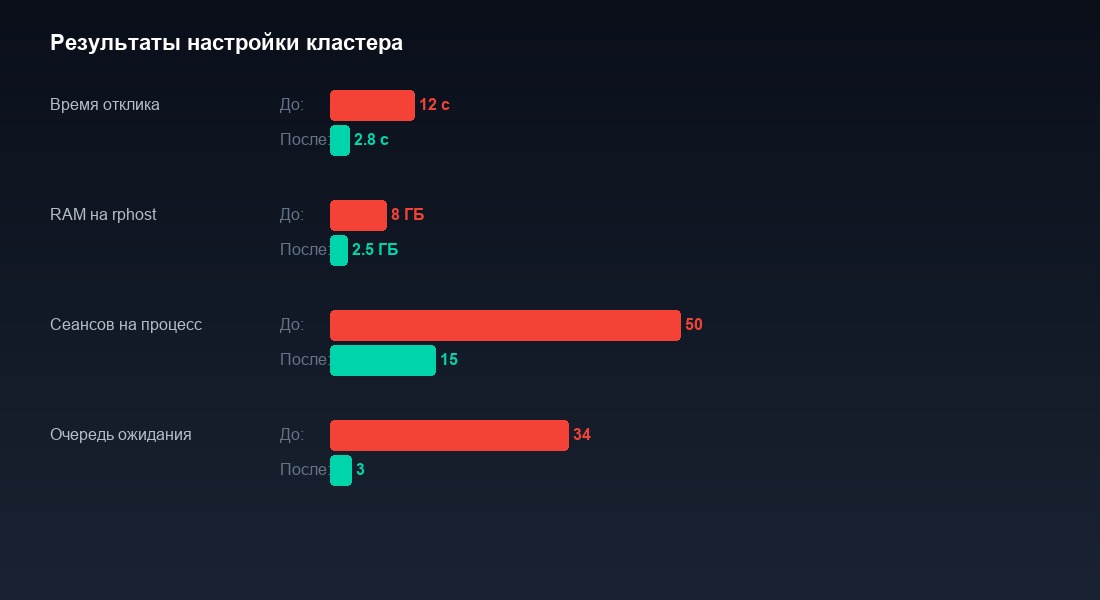
В нашем кейсе с 200 пользователями настройка кластера заняла 40 минут. Установили 6 рабочих процессов, лимиты памяти 4/6/8 ГБ, перезапуск раз в сутки в 3:00, балансировку по производительности. Время проведения документов после обеда снизилось с 40 секунд до 3. Ни одной строки кода не изменили — причина тормозов была не в коде, а в инфраструктуре кластера.
Через неделю IT-директор прислал графики: потребление памяти rphost стабильно держится в пределах 3-5 ГБ, время отклика не деградирует к вечеру, ночные перезапуски проходят незаметно. Сервер с теми же 64 ГБ RAM и 24 ядрами справляется с 200 пользователями без запинки. Не потому, что стал мощнее. Потому что начал использовать свои ресурсы правильно.
Настройки кластера — одна из первых вещей, которые мы проверяем при любом обращении по производительности. Чаще всего они стоят по умолчанию. И чаще всего именно это — корень проблемы.
Мониторинг после настройки. Настроить кластер — половина дела. Вторая половина — убедиться, что настройки работают и через месяц. Мы рекомендуем настроить автоматический мониторинг через скрипты на базе rac. Простой bash-скрипт, который раз в 5 минут выполняет rac process list, парсит memory-size каждого rphost и отправляет алерт, если значение превышает 80% от допустимого лимита. Это позволяет поймать аномалию до того, как сработает принудительный перезапуск. Дополнительно стоит логировать количество соединений на каждом rphost и соотношение enabled/disabled процессов. Если кластер часто отключает процессы (is-enable = no), значит, лимиты слишком жёсткие или нагрузка выросла и пора добавлять ресурсы. Скрипт на 30 строк, запущенный через cron, заменяет ручную проверку и предотвращает повторение ситуации «к обеду всё тормозит».