Рассылка отчётов запускается ночью. В 6 утра администратор видит: процесс всё ещё работает. 4 часа на 60 отчётов. Что-то не так. Или всё-таки так?
12 получателей, каждому — по 5 отчётов. 60 формирований. Каждый отчёт строится от 2 до 8 минут. Но половина получателей получает одинаковые отчёты: менеджеры одного отдела видят одну и ту же аналитику по подразделению. Один и тот же отчёт формируется 4 раза — для четырёх человек. Четыре раза тяжёлый запрос к СУБД. Четыре раза компоновка. Четыре раза сохранение в XLSX.
Кэширование решает эту задачу за 38 минут вместо четырёх часов. Но прежде чем кэшировать что-то своё — разберёмся, что 1С уже кэширует без нашего участия.
Виды кэширования в 1С
Кэширование в 1С — не одна технология. Это шесть уровней, каждый со своей механикой, своими ограничениями и своими граблями. Разработчик, который не понимает эту иерархию, рискует либо дублировать то, что платформа уже делает, либо сломать то, что работало.
Кэш СУБД. SQL Server (или PostgreSQL) кэширует данные и планы запросов в оперативной памяти. Повторный запрос к тем же данным не идёт на диск — результат берётся из буферного пула. Это работает автоматически, настраивается на уровне СУБД, и разработчик 1С на это не влияет напрямую. Но может влиять косвенно: неправильная структура запроса с условиями в неподходящем месте может заставить оптимизатор каждый раз строить новый план вместо использования кэшированного. Параметризованные запросы попадают в кэш планов. Запросы с литералами — нет. 1С генерирует параметризованные запросы, но динамические отборы в СКД иногда ломают эту схему.
Объектный кэш платформы (CacheSlidingWindow). Платформа 1С хранит в памяти рабочего процесса (rphost) прочитанные объекты: элементы справочников, записи регистров, метаданные. Повторное обращение к тому же объекту в рамках одного серверного вызова берёт данные из кэша, минуя СУБД. Размер кэша регулируется параметром кластера. По умолчанию работает скользящее окно: при нехватке памяти вытесняются наименее востребованные объекты. Этот кэш — причина, по которой первое открытие формы всегда медленнее последующих.
Сеансовые данные (SessionData). Каждый сеанс пользователя хранит свои данные в памяти сервера: содержимое реквизитов формы, временные таблицы, данные расшифровки отчётов, состояние динамических списков. Эти данные не разделяются между сеансами. При 100 активных сеансах — 100 копий сеансовых данных. Формально это не кэш, но потребляет память как кэш и ведёт себя как кэш. Один пользователь, открывший 15 форм и 3 отчёта, может занимать 200-400 МБ сеансовых данных.
Повторное использование возвращаемых значений. Директива общего модуля «ПовторноеИспользованиеВозвращаемыхЗначений». Вызов функции с теми же параметрами возвращает кэшированный результат без повторного выполнения кода. Два варианта: НаВремяВызова (кэш живёт до конца серверного вызова) и НаВремяСеанса (кэш живёт всю сессию пользователя). Мощный инструмент. Опасный инструмент.
HTTP-кэширование. Для интеграций через HTTP-сервисы 1С. Заголовки Cache-Control, ETag, Last-Modified позволяют клиенту или промежуточному прокси кэшировать ответы HTTP-сервиса. Работает только для операций чтения, только для HTTP-интерфейса. Но при правильной настройке снижает нагрузку на сервер 1С в разы — особенно когда внешняя система запрашивает одни и те же данные каждые 10 секунд.
Собственный кэш. Разработчик сам проектирует хранилище: регистр сведений, временное хранилище, файл на диске, внешняя key-value база (Redis, Memcached через HTTP). Полный контроль над архитектурой, временем жизни, инвалидацией. И полная ответственность за всё, что пойдёт не так.

Повторное использование: мощь и подводные камни
Директива модуля «ПовторноеИспользованиеВозвращаемыхЗначений» — самый популярный и самый опасный вид кэширования среди разработчиков 1С. Ставим галочку в свойствах общего модуля — и все функции этого модуля начинают кэшировать результат. Просто? Да. Безопасно? Категорически нет.
НаВремяВызова (ForCallDuration). Кэш существует в рамках одного серверного вызова. Пользователь нажал кнопку «Провести» — сервер получил вызов, обработал, вернул результат. Всё, кэш уничтожен. Безопасный вариант. Если функция получения ставки НДС вызывается 50 раз за одно проведение документа с 50 строками табличной части — результат вычислится один раз. При следующем проведении — вычислится заново. Данные всегда актуальны. Риск устаревания — ноль.
НаВремяСеанса (ForSessionDuration). Кэш живёт, пока живёт сеанс пользователя. Это рабочий день. 8-10 часов. Иногда сутки — если пользователь забыл закрыть 1С. Если кэшируемые данные изменились за это время — функция вернёт устаревший результат. Молча. Без ошибок. Без предупреждений. Пользователь не увидит изменений, пока не перезайдёт в программу.
Типичная ошибка: кэширование курсов валют НаВремяСеанса. Утром доллар был 3.25. В обед бухгалтер загрузил свежий курс — 3.28. Менеджер, который зашёл утром и не перезаходил, продолжает видеть 3.25 в документах. Документы проводятся с неправильным курсом. Бухгалтер обнаруживает расхождения через неделю при сверке. К этому моменту перепроводить нужно 80 документов.
Сбросить кэш вручную можно вызовом ОбновитьПовторноИспользуемыеЗначения(). Но его нужно вызвать в правильный момент и в правильном сеансе. А правильный момент — при каждом изменении кэшируемых данных. Если данные меняются из другого сеанса (а именно так обычно и бывает) — ваш сеанс об этом не узнает. Вызывать ОбновитьПовторноИспользуемыеЗначения() по таймеру? Можно, но тогда теряется весь смысл кэширования НаВремяСеанса — с тем же успехом используйте НаВремяВызова.
Правило, которого мы придерживаемся: НаВремяСеанса — только для данных, которые гарантированно не меняются в течение сеанса. Настройки конфигурации, значения функциональных опций, константы, которые правят раз в год, структура метаданных. Для всего остального — НаВремяВызова или собственный кэш с контролируемой инвалидацией.
Ещё один нюанс, который часто пропускают. Кэш работает по точному совпадению параметров функции. Функция ПолучитьЦену(Номенклатура, Дата) вызвана с параметрами (Ссылка1, 01.03.2026). Результат закэширован. Вызов с параметрами (Ссылка1, 02.03.2026) — промах кэша, вычисление заново. Вызов с параметрами (Ссылка2, 01.03.2026) — тоже промах. Каждая уникальная комбинация параметров — отдельная запись в кэше.
А если функция принимает структуру или массив — кэширование не работает вообще. Платформа не умеет сравнивать сложные типы для определения попадания в кэш. Каждый вызов будет обработан как уникальный, результат будет сохранён в кэш, но никогда не будет найден при повторном вызове. Память тратится, ускорения нет. Чистый убыток.
На одном проекте мы видели модуль с повторным использованием, в котором было 40 функций. Из них реально выигрывали от кэширования три. Остальные 37 вызывались по одному разу за серверный вызов или принимали сложные типы. Кэш не помогал, но отъедал память под хранение ненужных результатов. Мы вынесли 37 функций в обычный модуль без повторного использования — потребление RAM на рабочем процессе упало на 180 МБ. Производительность не изменилась. Стабильность выросла.
Кэширование отчётов: кейс из практики
Проект NOYAKS. Производственная компания, 1С:ERP. Система рассылки управленческих отчётов руководителям. Каждое утро к 7:00 на email каждого руководителя должен прийти набор отчётов за вчерашний день. Генеральный директор, финансовый директор, руководители подразделений, ключевые менеджеры — 12 человек.
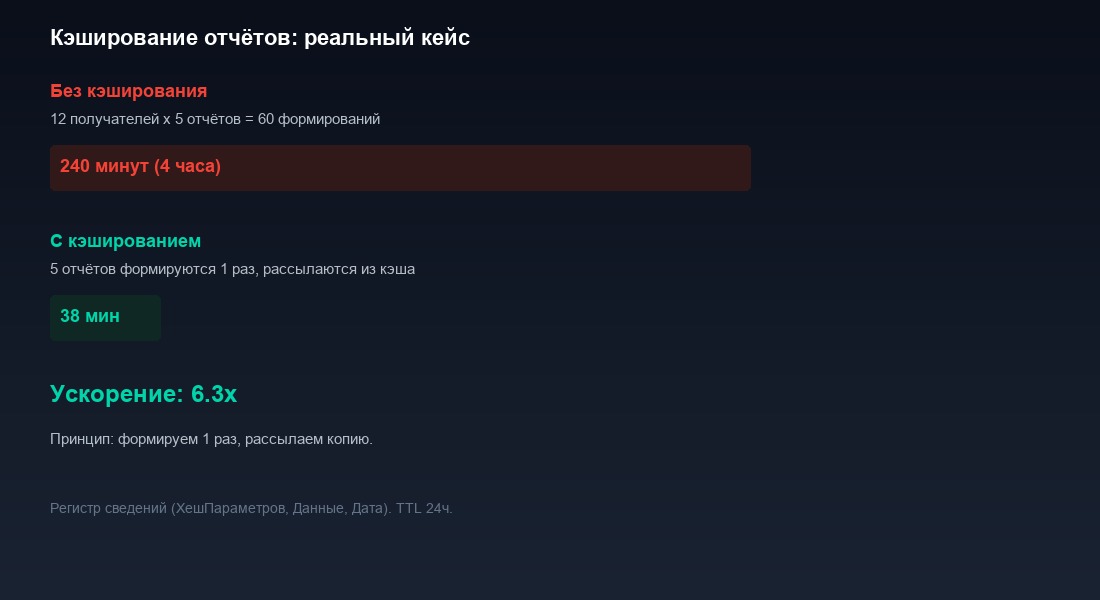
12 получателей. 5 отчётов каждому. 60 формирований. Запуск в 3:00 ночи. Окончание — 7:10, 7:30, иногда 8:00. Руководители приходят на работу и не видят свежих отчётов. Недовольство растёт.
Мы подключились к замеру. Среднее время формирования одного отчёта — 3 минуты 48 секунд. Самый лёгкий (остатки по складу) — 1 минута 50 секунд. Самый тяжёлый (P&L с детализацией по ЦФО) — 7 минут 20 секунд. 60 отчётов последовательно — 228 минут. Почти четыре часа. Математика сходится. Процесс работает ровно столько, сколько должен при последовательном формировании.
Но вот что интересно. Мы выгрузили параметры всех 60 формирований в таблицу и сравнили. Из 60 формирований уникальных — 22. Остальные 38 — полные дубли. Четыре менеджера отдела продаж получают один и тот же отчёт «Продажи по менеджерам» с одинаковыми параметрами. Три директора филиалов — один и тот же «P&L по компании». Шесть человек — «Остатки на складах» без каких-либо индивидуальных отборов. Система честно формирует каждый отчёт заново, даже если точно такой же был сформирован 10 минут назад.
Решение напрашивается: формировать каждый уникальный отчёт один раз, сохранять результат, отправлять из сохранённого. Классическое кэширование с хэш-ключом.
Архитектура кэша. Регистр сведений «КэшОтчётов». Измерения: ХэшПараметров (строка, 64 символа — SHA-256 в HEX), КлючОтчёта (строка, 128 символов — для человекочитаемой идентификации). Ресурсы: ДвоичныеДанные (хранилище значения — сам файл отчёта в формате XLSX), ДатаФормирования (дата-время — когда отчёт был сгенерирован), РазмерБайт (число — для мониторинга объёма кэша).
Хэш параметров. Каждый отчёт определяется набором параметров: имя отчёта, период начала и конца, организация, подразделение, дополнительные отборы (если есть), вариант отчёта. Мы сериализуем все параметры в каноническую строку (отсортированные ключи, фиксированный формат дат), вычисляем SHA-256 хэш. Одинаковые параметры — одинаковый хэш — попадание в кэш. Разные параметры — разный хэш — формирование отчёта.
Почему SHA-256, а не MD5 или CRC32? Не из-за криптографической стойкости — это кэш, а не подпись. Из-за длины хэша и вероятности коллизий. При 10 000 уникальных отчётов в месяц вероятность коллизии SHA-256 пренебрежимо мала. MD5 тоже подошёл бы, но SHA-256 — стандартная функция в БСП, не нужно ничего импортировать.
Логика работы. Перед формированием отчёта обработка рассылки вычисляет хэш параметров и проверяет: есть ли в регистре запись с таким хэшем? Если да и ДатаФормирования не старше 24 часов — берём ДвоичныеДанные из кэша, прикрепляем к письму, отправляем. Если нет — формируем отчёт штатным способом, сохраняем XLSX как двоичные данные в регистр, отправляем.
Первый получатель отчёта «Остатки на складах» ждёт 1 минуту 50 секунд — отчёт формируется. Остальные пятеро получают тот же отчёт за 2-3 секунды каждый — из кэша.
Результат. 22 уникальных отчёта формируются за 22 x 3.8 минуты = 83 минуты. Плюс 38 отправок из кэша — по 2-3 секунды каждая (чтение из регистра + формирование письма). Итого при последовательном выполнении: 85 минут. Уже в 2.7 раза быстрее.
Но мы не остановились. Добавили параллельное формирование: три фоновых задания, каждое берёт из очереди следующий неформированный отчёт. Три потока параллельно — 83 минуты делим на 3 — получаем примерно 28 минут на формирование. Плюс 10 минут на отправку 60 писем (часть последовательно, чтобы не перегрузить SMTP). Итого: 38 минут.
С 4 часов до 38 минут. В 6.3 раза быстрее. Все отчёты в почте руководителей к 3:40 ночи.
TTL и инвалидация. Время жизни кэша — 24 часа. Рассылка ежедневная, данные за вчера не меняются при нормальном ходе работы. Регламентные операции типа закрытия месяца выполняются до начала рассылки — это зафиксировано в расписании. Но бывают исключения: пересчёт себестоимости, корректирующие проводки задним числом. Для таких случаев мы добавили ручную инвалидацию — кнопку «Очистить кэш и переформировать» в обработке управления рассылкой. Нажал — все записи регистра удалены, следующий запуск рассылки формирует всё заново.
Контроль размера. Один отчёт в XLSX — от 200 КБ до 5 МБ, в зависимости от количества данных и сложности форматирования. 22 уникальных отчёта в день — до 110 МБ. За месяц — 3.3 ГБ. За год — 40 ГБ. Это уже ощутимо для базы данных. Поэтому регламентное задание «ОчисткаКэшаОтчётов» запускается ежедневно в 2:00 (за час до рассылки) и удаляет записи старше 7 дней. Неделя — достаточный запас, чтобы переотправить отчёт руководителю, который не получил письмо. И достаточно короткий срок, чтобы регистр не разрастался.
Мониторинг. Раз в сутки регламентное задание пишет в журнал регистрации: количество записей в кэше, суммарный объём в МБ, количество попаданий в кэш за последние сутки, количество промахов. Если процент попаданий падает ниже 40% — значит, поменялась структура рассылки и стоит пересмотреть список получателей. Если объём кэша превышает 500 МБ — значит, отчёты стали тяжелее и нужно разобраться почему.
Четыре ошибки при кэшировании
Кэширование — не бесплатный обед. Каждый кэш — это техническое обязательство. Мы видели проекты, где неправильный кэш создавал больше проблем, чем решал.
Ошибка 1: устаревшие данные без механизма обнаружения. Кэшировали справочник контрагентов НаВремяСеанса. Менеджер создал нового контрагента в своём сеансе. Другой менеджер не видит его в списке выбора — кэш возвращает старый список. Перезаход помогает, но пользователь не знает, что нужно перезайти. И не должен знать — это не его забота. Результат: «у нас программа глючит, контрагент то появляется, то пропадает, уже третий раз за неделю звоню в поддержку». Поддержка не может воспроизвести — у них свежий сеанс, кэш чистый, всё работает. Замкнутый круг.
Ошибка 2: утечка памяти через кэш. Кэшировали результат запроса, возвращающего таблицу значений на 50 000 строк. Режим — НаВремяСеанса. 80 активных сеансов. Каждый сеанс — своя копия таблицы. 80 x 50 МБ = 4 ГБ RAM на один кэшированный запрос. А таких запросов в модуле было три. Rphost раздулся до 12 ГБ, потом до 14. Начался своппинг. SQL Server лишился памяти, потому что rphost забрал всё. Сервер 1С перезапустился аварийно. Все пользователи отключились. Фактически кэш, призванный ускорить работу, положил весь сервер.
Ошибка 3: кэш без механизма очистки. Записали данные в регистр сведений как собственный кэш расчётов. Забыли добавить регламентное задание очистки. Через полгода регистр — 15 ГБ. Бэкап базы вырос в два раза. Регламентное обслуживание SQL Server (реиндексация, обновление статистики) занимает на час дольше. Полнотекстовый поиск индексирует этот регистр и тратит ресурсы впустую. Никто не заметил, пока не закончилось место на диске. Удаление 15 ГБ из регистра сведений заняло 40 минут и заблокировало базу — пришлось делать ночью.
Ошибка 4: преждевременная оптимизация. Разработчик прочитал статью про кэширование (возможно, эту) и решил закэшировать функцию получения настроек печатных форм. Функция вызывается при нажатии кнопки «Печать» — 3-5 раз в день у одного пользователя. Время выполнения — 0.1 секунды. Экономия от кэширования — 0.5 секунды в день на всех пользователей. Разработка кэша, тестирование, документация — 8 часов. При зарплате разработчика ROI этого решения выйдет в плюс через 160 лет. Кэшировать стоит только горячие пути — то, что вызывается тысячи раз в день или то, что выполняется минуты, а не доли секунды.

Когда кэшировать, а когда нет
Прежде чем писать кэш — замерь. Это не совет из учебника. Это правило, выработанное на десятках проектов. Мы видели случаи, когда разработчик «точно знал», что вот этот запрос тормозит — он же сложный, там четыре соединения таблиц. Добавлял кэш. Потом мы включали технологический журнал и обнаруживали: запрос выполнялся 0.02 секунды. А тормозило открытие формы из-за того, что в обработчике ПриСозданииНаСервере вызывалось 15 HTTP-запросов к внешнему сервису. Кэш запроса не помог. Вообще.
Замер первичен. Технологический журнал, замер производительности, APDEX — любой инструмент, который показывает реальные цифры, а не предположения. Нашли горячую точку — тогда думаем про кэш. Не нашли — не кэшируем.
Фреймворк принятия решения, который мы используем:
- Функция вызывается больше 100 раз за серверный вызов с одними и теми же параметрами? ПовторноеИспользование НаВремяВызова. Безопасно, эффективно, ноль рисков устаревания. Типичный пример: получение ставки НДС при проведении документа с большой табличной частью.
- Данные гарантированно не меняются в течение сеанса? ПовторноеИспользование НаВремяСеанса. Константы, настройки конфигурации, функциональные опции, версия конфигурации, перечень доступных ролей.
- Данные редко меняются, но читаются часто из разных сеансов? Собственный кэш с TTL. Регистр сведений + регламентное задание очистки + мониторинг размера.
- Одинаковые тяжёлые вычисления для разных потребителей? Собственный кэш с хэш-ключом. Как в кейсе с отчётами NOYAKS.
- Данные меняются часто и непредсказуемо? Не кэшировать. Стоимость надёжной инвалидации превысит выигрыш от кэширования. Лучше оптимизировать сам запрос.
Простая инвалидация всегда лучше сложной. Если вы не можете объяснить в одном предложении, когда и как кэш очищается — архитектура слишком сложная. Упрощайте. TTL 5 минут с полной очисткой — грубо, зато надёжно и предсказуемо. Точечная инвалидация по событиям из 12 подсистем — элегантно на бумаге, но сломается на третьей неделе эксплуатации, когда кто-то добавит 13-ю подсистему и забудет про инвалидацию.
Кэширование — это компромисс между скоростью и актуальностью данных. Ускорение всегда чего-то стоит: памяти, свежести данных, сложности кода, времени на сопровождение. Не существует бесплатного кэша. Каждый раз, добавляя кэш, мы берём на себя обязательство: следить за его размером, гарантировать инвалидацию, мониторить эффективность, документировать поведение для тех, кто придёт после нас.
В кейсе NOYAKS кэш отчётов окупился за первую неделю. Но мы потратили два дня на проектирование архитектуры, написание кода, тестирование, настройку мониторинга и документирование. Потому что знали: если кэш сломается — руководители не получат отчёты. А это хуже, чем получить их на два часа позже.
Если замер показывает, что кэш нужен — кэшируйте осознанно. Если замер не сделан — сначала замерьте. В половине случаев окажется, что проблема не в скорости чтения, а в структуре запроса или в инфраструктуре. И тогда вместо кэша нужен рефакторинг запроса или настройка сервера.