Пятница, восемь вечера. Звонок. Обмен с кассами розничной сети остановился. 47 магазинов не получают обновления цен и номенклатуры. Кассиры сканируют товар — система говорит «штрихкод не найден». Очереди на кассах растут. Телефон руководителя IT-отдела разрывается от звонков директоров магазинов.
HTTP-сервис 1С, который обеспечивал обмен, молча перестал отвечать. Ни ошибок в логе, ни аварийных завершений. Просто тишина. Запросы зависали и отваливались по тайм-ауту через 60 секунд. Причина — deadlock, которого не было ни в одном учебнике по 1С.
Как устроен HTTP-сервис 1С изнутри
HTTP-сервис 1С — это код на языке 1С, который обрабатывает HTTP-запросы. Снаружи он выглядит как обычный REST API: принимает GET/POST, возвращает JSON или XML. Изнутри архитектура значительно сложнее, чем кажется при первом знакомстве.
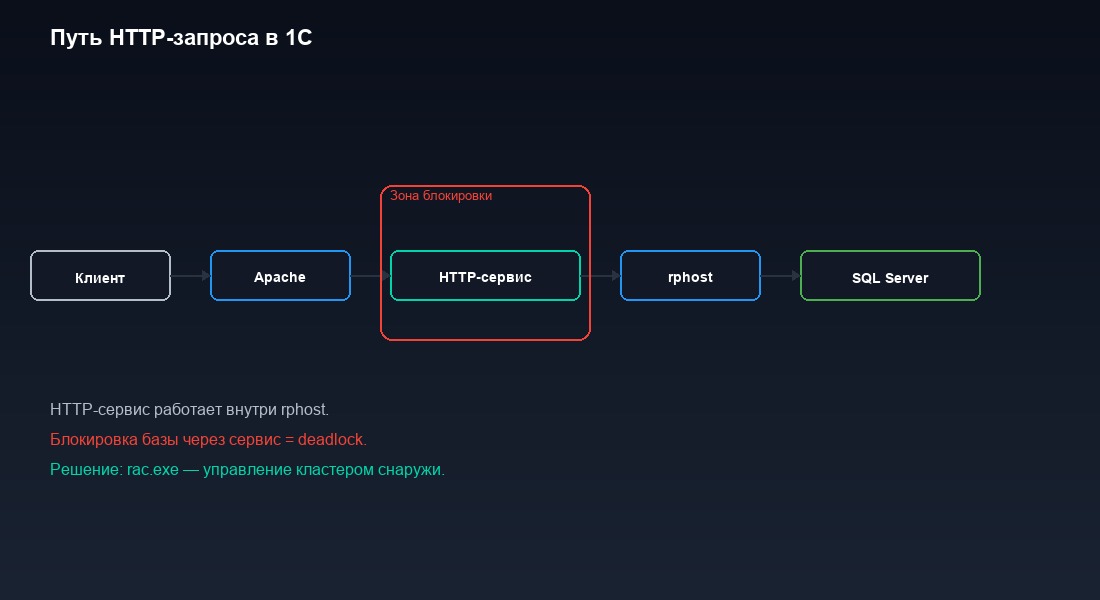
Цепочка обработки запроса: внешний клиент (касса, мобильное приложение, сайт) отправляет HTTP-запрос. Его принимает веб-сервер — Apache или IIS. Веб-сервер через модуль расширения 1С (wsap24.dll для Apache, wsisapi.dll для IIS) передаёт запрос рабочему процессу rphost. Модуль расширения — это динамическая библиотека, которая поддерживает пул соединений с кластером 1С. Она не создаёт новое соединение на каждый запрос, а берёт свободное из пула. Rphost находит нужный HTTP-сервис в метаданных конфигурации, вызывает обработчик на языке 1С. Обработчик выполняет бизнес-логику — обычно это запросы к базе через SQL Server — формирует ответ и возвращает его обратно по цепочке.
Ключевой момент: HTTP-сервис работает внутри rphost. Того самого rphost, который обслуживает обычных пользователей. Того самого, который является частью кластера 1С. HTTP-сервис — не отдельный изолированный компонент. Он живёт в общем адресном пространстве и подчиняется всем правилам кластера.
Это имеет конкретные последствия. Блокировка информационной базы для обновления — HTTP-сервис перестаёт работать. Перезапуск рабочего процесса по лимиту памяти — HTTP-запросы прерываются. Регламентное задание нагрузило rphost тяжёлым расчётом — HTTP-сервис замедляется. Пользователь запустил отчёт за год — HTTP-сервис ждёт, пока rphost освободит ресурсы.
Deadlock, который никто не ожидал
Контекст: CI/CD для проекта 1С. Автоматическое развёртывание обновлений конфигурации. Процесс стандартный: заблокировать базу, выкинуть пользователей, обновить конфигурацию, применить обновление базы данных, снять блокировку. Для автоматизации использовался тот же HTTP-сервис, который обслуживал обмен с магазинами. Логика казалась разумной: HTTP-сервис может вызывать серверный код 1С, значит, через него можно управлять блокировкой базы. Разработчик добавил метод /api/deploy/lock и /api/deploy/unlock в существующий HTTP-сервис.
Проблема выявилась при первом же реальном деплое в production. Скрипт CI/CD отправил HTTP-запрос POST /api/deploy/lock. HTTP-сервис принял запрос, начал выполнять код блокировки. Код вызвал УстановитьБлокировкуСоединенийИнформационнойБазы(). Блокировка установлена. А дальше — тупик.
HTTP-сервис работает внутри rphost. Rphost — часть кластера. Блокировка базы распространяется на весь кластер. HTTP-сервис заблокировал базу, в которой сам же работает. Следующий запрос — POST /api/deploy/unlock — требует нового соединения с базой. Но новые соединения запрещены — база заблокирована. Запрос на снятие блокировки отклоняется с ошибкой «начало сеанса запрещено». Deadlock.
Ситуация усугубилась двумя обстоятельствами. Во-первых, блокировка была установлена с кодом разрешения. Чтобы подключиться к заблокированной базе, нужно передать этот код в параметрах соединения. HTTP-сервис не может передать код разрешения при установке собственного соединения — он подключается через пул модуля расширения, который ничего не знает о кодах разрешения. Во-вторых, блокировка была установлена на 4 часа вперёд для запаса. Пятница, восемь вечера. Блокировка снимется автоматически в полночь. Четыре часа без обмена с магазинами.
Ручное снятие через консоль администрирования кластера возможно. Но CI/CD-скрипт этого не умеет, дежурного администратора в пятницу вечером нет, а IT-директор не имеет доступа к консоли кластера — только к веб-клиенту 1С. Проблему решили удалённым подключением к серверу через TeamViewer по звонку системному администратору.
Решение, к которому мы пришли: управление блокировкой базы не через HTTP-сервис 1С, а напрямую через rac.exe по RAS-порту. Rac работает на уровне агента сервера, вне контекста информационной базы. Ему не нужно соединение с базой, чтобы управлять ею. Rac общается с ragent, а не с rphost.
# Установить блокировку
rac infobase update --cluster=<cluster-id> --infobase=<ib-id> \
--sessions-deny=on --denied-from="2026-03-13T22:00:00" \
--permission-code="deploy123" \
--cluster-admin=admin --cluster-pwd=pwd
# Снять блокировку
rac infobase update --cluster=<cluster-id> --infobase=<ib-id> \
--sessions-deny=off \
--cluster-admin=admin --cluster-pwd=pwdRac обращается к ragent напрямую через порт 1545. Ragent управляет кластером снаружи, а не изнутри рабочего процесса. Никакого deadlock. CI/CD-скрипт вызывает rac, блокирует базу, выкидывает сеансы, обновляет конфигурацию, применяет обновление БД, снимает блокировку. HTTP-сервис в этом процессе не участвует.
Мы также добавили в CI/CD-скрипт проверку: если блокировка не снялась за 10 минут — скрипт автоматически вызывает rac infobase update --sessions-deny=off через отдельный таймер. Страховка от зависания обновления.
Урок: HTTP-сервис 1С — это код внутри базы. Управлять базой изнутри неё самой — ловушка. То же самое касается любых административных операций: не пытайтесь через HTTP-сервис выгружать пользователей, менять параметры кластера или управлять регламентными заданиями в контексте деплоя. Используйте rac. Инфраструктурные проблемы требуют инфраструктурных инструментов, а не прикладного кода.
Монолит в 2800 строк
Второй кейс. Тот же клиент, полгода спустя. Deadlock починили, CI/CD работает штатно. Но HTTP-сервис обмена с магазинами стал медленным. Среднее время ответа — 4500 мс. При 47 магазинах и обмене каждые 5 минут сервис не успевал обработать все запросы до следующего цикла. Очередь росла. К вечеру задержка обмена достигала 40 минут. Магазин отправляет данные о продажах за последний час, а 1С получает их только через 40 минут. Для оперативного управления остатками это неприемлемо.
Открыли модуль HTTP-сервиса. 2800 строк в одном модуле. Один метод-обработчик на 1900 строк. Внутри — всё: парсинг входящего JSON, валидация данных, поиск номенклатуры, создание документов, формирование ответа. Без разделения на функции. Без промежуточных переменных с осмысленными именами. Копипаста одних и тех же блоков для разных типов документов — реализация, возврат, инвентаризация. Три варианта одного и того же кода с минимальными отличиями.
Но главная проблема — не в читаемости. Главная проблема — запрос в цикле.
Входящий JSON содержал документ реализации с табличной частью. 50-300 строк в среднем, в пиках — до 500. Для каждой строки сервис выполнял отдельный запрос к базе: найти номенклатуру по штрихкоду, проверить остатки на складе, получить текущую цену. Три запроса на строку. Документ из 200 строк — 600 запросов к SQL Server.
Каждый запрос — это обращение к rphost, трансляция запроса 1С в SQL, отправка на сервер БД, ожидание ответа, возврат результата. 5-8 мс на запрос при холодном кэше, 2-3 мс при тёплом. 600 запросов при среднем времени 5 мс — 3 секунды только на обращения к базе. Плюс накладные расходы на создание и уничтожение объектов Запрос в цикле, плюс десериализация результатов, плюс логика обработки. Итого — 4.5 секунды на один документ.
Это классический антипаттерн, который мы встречаем постоянно. Его легко допустить: код пишется «по строке», разработчик думает в терминах одной строки документа, а не пакета. На тестовой базе с документами по 5 строк всё работает мгновенно. На production с документами по 200 строк — коллапс. Проблема нарастает постепенно: сначала документы маленькие, потом ассортимент растёт, строк становится больше, и в один момент HTTP-сервис перестаёт укладываться в тайм-аут.
Рефакторинг: три модуля вместо одного
Рефакторинг мы начали с декомпозиции. Монолитный обработчик разбили на три модуля, оформленных как общие модули конфигурации:
- Модуль парсинга и валидации (HTTPОбменПарсинг). Принимает HTTP-запрос, десериализует JSON через
ПрочитатьJSON(), проверяет обязательные поля (дата, номер, тип документа, табличная часть), приводит типы данных. Если данные невалидны — немедленный ответ с кодом 400 и описанием ошибки на русском языке. До базы данных запрос не доходит. Модуль: 180 строк. - Модуль бизнес-логики (HTTPОбменОбработка). Получает структурированные данные от парсера в виде таблицы значений. Выполняет поиск номенклатуры, проверку остатков, создание и проведение документов. Вся работа с базой данных — здесь. Модуль: 350 строк.
- Модуль формирования ответа (HTTPОбменОтвет). Получает результат от бизнес-логики (структуру с массивом ошибок и созданными документами), сериализует в JSON через
ЗаписатьJSON(), формирует HTTP-ответ с правильными заголовками и кодами состояния. Модуль: 120 строк.
Декомпозиция сама по себе не ускорила сервис. Время ответа осталось тем же — 4500 мс. Зато мы получили возможность точно измерить, где тратится время. Парсинг — 15 мс. Бизнес-логика — 4400 мс. Формирование ответа — 12 мс. Узкое место очевидно.
Ускорение дала замена запросов в цикле на пакетные запросы.
Вместо 600 отдельных запросов — один. Собираем все штрихкоды из входящего документа в таблицу значений. Передаём таблицу в запрос как параметр. Один запрос возвращает номенклатуру, остатки и цены для всех строк сразу. SQL Server оптимизирует такой запрос несравнимо лучше, чем 600 одиночных: один план выполнения, одно обращение к индексам, один проход по таблицам. Кэш страниц SQL Server прогревается один раз, а не 600.
Код до рефакторинга (упрощённо):
Для Каждого Строка Из ТаблицаСтрок Цикл
Запрос = Новый Запрос;
Запрос.Текст = "ВЫБРАТЬ Номенклатура ИЗ Справочник.Номенклатура
|ГДЕ ШтрихКод = &ШК";
Запрос.УстановитьПараметр("ШК", Строка.Штрихкод);
Результат = Запрос.Выполнить();
// ... обработка
КонецЦикла;Код после:
Запрос = Новый Запрос;
Запрос.Текст = "ВЫБРАТЬ
| Штрихкоды.Штрихкод КАК Штрихкод,
| Номенклатура.Ссылка КАК Номенклатура,
| Остатки.КоличествоОстаток КАК Остаток
|ИЗ &Штрихкоды КАК Штрихкоды
| ЛЕВОЕ СОЕДИНЕНИЕ Справочник.Номенклатура КАК Номенклатура
| ПО Штрихкоды.Штрихкод = Номенклатура.ШтрихКод
| ЛЕВОЕ СОЕДИНЕНИЕ РегистрНакопления.ТоварыНаСкладах.Остатки КАК Остатки
| ПО Номенклатура.Ссылка = Остатки.Номенклатура";
Запрос.УстановитьПараметр("Штрихкоды", ТаблицаШтрихкодов);
Результат = Запрос.Выполнить();Обратите внимание на LEFT JOIN. При работе с левым соединением критически важно правильно размещать условия фильтрации — в ON, а не в WHERE. Иначе LEFT JOIN превращается в INNER JOIN, и строки без остатков исчезают из результата. В нашем случае это означало бы потерю позиций документа, для которых нет остатков на складе. Мы видим эту ошибку в каждом втором проекте, и в HTTP-сервисах она особенно коварна: данные молча теряются, а клиент получает неполный ответ.
Помимо основного запроса, мы объединили проверку цен в тот же пакетный запрос через вложенный запрос к регистру цен. Три отдельных запроса на строку превратились в один пакетный запрос на весь документ. SQL Server обработал его за одно обращение.
Результат рефакторинга: время ответа снизилось с 4500 мс до 280 мс. В 16 раз. Один запрос вместо 600 — и SQL Server делает всю работу за одно обращение вместо шестисот.
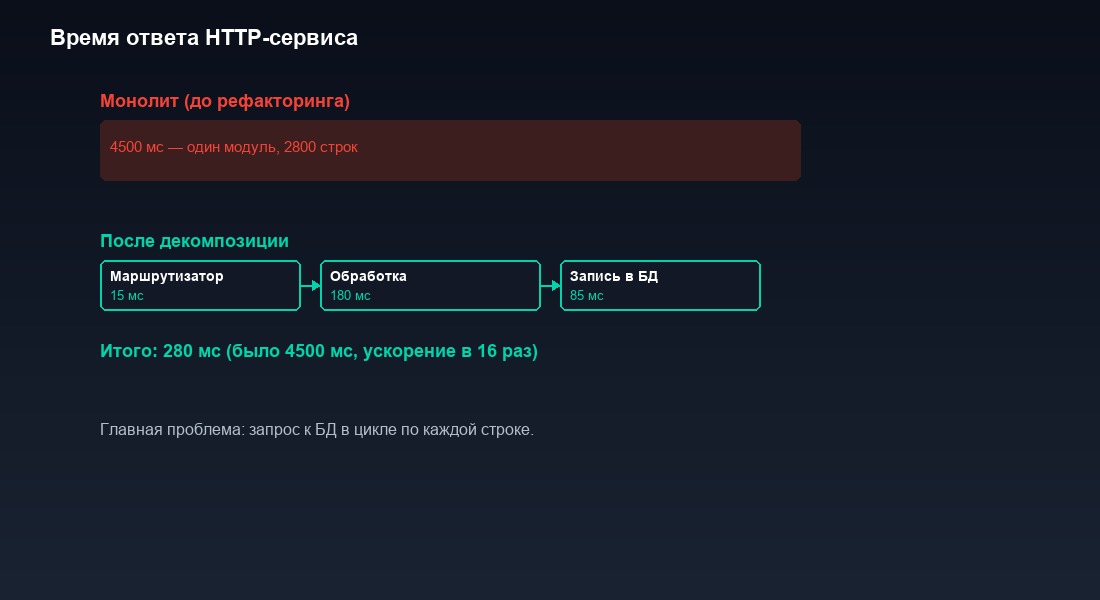
Дополнительно мы добавили логирование времени выполнения каждого этапа в регистр сведений. Парсинг — 15 мс. Запрос к базе — 180 мс. Создание документа — 55 мс. Формирование ответа — 12 мс. Накладные расходы HTTP — 18 мс. Итого 280 мс. Теперь при любой деградации мы сразу видим, какой этап замедлился, без необходимости подключать отладчик или технологический журнал.
Был и побочный эффект. С временем ответа 280 мс HTTP-сервис успевает обработать все 47 магазинов за один цикл обмена с запасом. Очередь исчезла. Задержка обмена сократилась с 40 минут до реального времени — данные из магазина попадают в базу за секунды.

Уроки для нагруженных сервисов
Два кейса — два разных типа проблем. Первый — архитектурный: попытка управлять базой изнутри неё самой. Второй — алгоритмический: запрос в цикле. Оба типичны для HTTP-сервисов 1С в production. Оба невидимы на тестовых стендах.
Вот правила, которые мы вывели из десятков подобных проектов:
Не смешивайте административные и бизнес-операции. HTTP-сервис — для обмена данными. Управление кластером, блокировки, деплой — через rac/ras. Это разные уровни архитектуры, и они не должны пересекаться в одном компоненте. Смешивание приводит к deadlock-ам, которые невозможно предсказать на этапе разработки и невозможно воспроизвести на тестовом стенде с одним пользователем.
Измеряйте время каждого этапа. Без метрик оптимизация превращается в гадание. Логируйте время парсинга, время запроса, время формирования ответа. Записывайте в регистр сведений с измерением «HTTPМетод» и ресурсами «ВремяПарсинг», «ВремяЗапрос», «ВремяОтвет». Когда сервис замедлится (а он замедлится с ростом данных) — вы будете точно знать, где искать. Бывает, что проблема вообще не в коде сервиса, а в инфраструктуре — перегруженном rphost, нехватке памяти, фрагментированных индексах SQL Server.
Никаких запросов в циклах. Ни одного. Всегда пакетный запрос через временную таблицу. Разница на 10 строках незаметна. На 200 строках — катастрофа. На 1000 строк (а такие документы бывают в оптовой торговле) — сервис просто не ответит в разумное время и отвалится по тайм-ауту веб-сервера.
Выделяйте HTTP-сервис в отдельный рабочий процесс. В настройках требований назначения функциональности кластера можно указать, что HTTP-сервисы обслуживаются выделенным rphost. Тогда тяжёлый отчёт пользователя за три года не повлияет на обмен с магазинами. И наоборот — пиковая нагрузка обмена (47 магазинов отправляют данные одновременно) не замедлит интерактивных пользователей.
Ограничивайте размер входящих данных. Проверяйте Content-Length до начала обработки. Если клиент отправил 50 МБ JSON — это либо ошибка, либо атака. Установите лимит (например, 5 МБ) и возвращайте 413 Payload Too Large. Также ограничивайте количество строк в документе: если пришло 10000 строк — это, скорее всего, ошибка на стороне клиента.
Используйте идемпотентность. Сеть ненадёжна. Запрос может отправиться дважды — клиент не получил ответ, отправил повторно. Если HTTP-сервис создаёт документ — добавьте проверку по уникальному идентификатору запроса (UUID, который генерирует клиент). Повторный запрос с тем же ID не должен создавать дубль. Он должен вернуть результат первого запроса.
Обрабатывайте ошибки внятно. HTTP-сервис должен возвращать структурированные ошибки, а не стек вызовов 1С. Код 400 — проблема в данных клиента. Код 500 — проблема на сервере. В теле ответа — JSON с полями error и message. Клиент должен понимать, что пошло не так, без звонка разработчику.
Держите модули компактными. 2800 строк в одном модуле — это не код, это свалка. 200-300 строк на модуль. Каждый модуль делает одну вещь. Парсинг отдельно. Валидация отдельно. Обращение к базе отдельно. Формирование ответа отдельно. Такой код легко тестировать, легко профилировать, легко менять. Когда через год придёт новый разработчик — он разберётся за час, а не за неделю.
HTTP-сервисы 1С — мощный инструмент интеграции. Но под нагрузкой они требуют тех же инженерных практик, что и любой backend: профилирование, пакетная обработка, декомпозиция, разделение ответственности. 1С не прощает пренебрежения этими практиками. Она просто молча останавливается в пятницу вечером.