Клиент решил уйти с Microsoft SQL Server на PostgreSQL. Причина стандартная — лицензии. SQL Server Standard стоит денег, PostgreSQL бесплатный. Экономия понятна. Подводные камни — нет.
Переезд прошёл за день. Выгрузка-загрузка через dt-файл, всё штатно. А потом начались звонки. Первый — через два дня. Последний — через три месяца. Пять проблем, которые мы собрали на одном проекте. Все — типичные.
Грабли первые: VACUUM не настроен
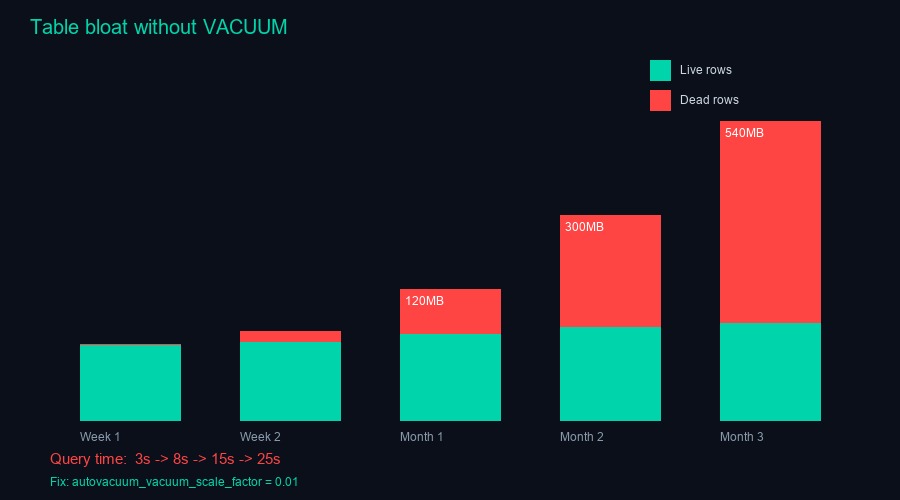
PostgreSQL не удаляет старые версии строк при UPDATE и DELETE. Он помечает их как мёртвые и оставляет в таблице. VACUUM — процесс, который чистит эти мёртвые строки. Без него таблицы распухают, индексы деградируют, запросы замедляются.
Autovacuum включён по умолчанию. Но его настройки рассчитаны на средние нагрузки. В 1С нагрузка специфическая: регистры накопления и бухгалтерии обновляются массово при проведении документов. Тысячи строк за одну транзакцию. Autovacuum не успевает.
Через месяц таблица регистра бухгалтерии выросла с 2 ГБ до 8 ГБ. Живых строк — на 2 ГБ. Остальное — мертвый груз. Запрос оборотно-сальдовой ведомости, который раньше выполнялся за 3 секунды, стал выполняться за 25.
Решение: настроить autovacuum агрессивнее для таблиц 1С. autovacuum_vacuum_scale_factor = 0.01 (вместо дефолтных 0.2). autovacuum_analyze_scale_factor = 0.005. Для самых нагруженных таблиц — ещё агрессивнее, через ALTER TABLE SET. И запланировать полный VACUUM ANALYZE раз в неделю в нерабочее время.
Грабли вторые: планы запросов и отсутствие хинтов
В SQL Server есть подсказки оптимизатору — query hints. OPTION (HASH JOIN), OPTION (RECOMPILE), FORCESEEK. 1С не использует их напрямую, но SQL Server хорошо понимает типичные паттерны запросов 1С и строит эффективные планы.
PostgreSQL использует другой оптимизатор. Он принимает другие решения. Запрос, который на SQL Server выполнялся с Index Seek за полсекунды, на PostgreSQL может выполняться с Seq Scan за 30 секунд. Не потому что PostgreSQL хуже — потому что статистика другая, стоимостные модели другие, и оптимизатор выбирает другой план.
Самая частая проблема — Nested Loop вместо Hash Join на больших выборках. PostgreSQL недооценивает количество строк, выбирает Nested Loop, и запрос улетает в космос.
Решение: регулярный ANALYZE (обновление статистики). Настройка random_page_cost (снизить с 4 до 1.1-1.5 для SSD-дисков — по умолчанию PostgreSQL считает, что random read в 4 раза дороже sequential, что верно для HDD, но не для SSD). И effective_cache_size — выставить в 75% оперативной памяти сервера.
Грабли третьи: блокировки и row-level locking
В SQL Server 1С использует управляемые блокировки через менеджер блокировок платформы. Это работает предсказуемо — разработчик контролирует гранулярность.
В PostgreSQL блокировки работают иначе. MVCC (Multi-Version Concurrency Control) даёт каждой транзакции свой снимок данных. Читатели не блокируют писателей. Звучит идеально. На практике — появляются дедлоки в местах, где на SQL Server их не было.
Типичный сценарий: два пользователя одновременно проводят документы, которые двигают один и тот же регистр накопления. На SQL Server менеджер блокировок 1С разрулит — поставит одного в очередь. На PostgreSQL транзакции стартуют параллельно, обе пытаются обновить одни и те же строки, одна получает deadlock detected.
Решение: проверить, что в конфигурации включён режим управляемых блокировок (а не автоматических). Если конфигурация старая и работает в автоматическом режиме — это первое, что нужно исправить перед переездом. Второе — настроить deadlock_timeout (по умолчанию 1 секунда, для 1С лучше 3-5 секунд, чтобы дать транзакциям время разрешиться самостоятельно).

Грабли четвёртые: кодировка и сортировка
При создании базы PostgreSQL нужно указать кодировку и локаль. Для 1С — только UTF-8 и локаль ru_RU.UTF-8 (или en_US.UTF-8). Если создать базу с неправильной локалью — русские символы будут сортироваться неправильно.
Звучит мелко. На практике: отчёт по контрагентам, отсортированный по алфавиту, показывает «Я» перед «А». Бухгалтер в шоке, звонит: «У вас программа сломалась».
Ещё хуже — локаль влияет на работу индексов. Если индекс создан с одной локалью, а запрос использует другую — индекс не используется. Seq Scan по таблице с миллионом строк.
Решение: при создании кластера PostgreSQL задать правильную локаль сразу. Проверить: SELECT datcollate, datctype FROM pg_database WHERE datname = current_database(). Если не ru_RU.UTF-8 — пересоздать кластер. Да, именно пересоздать. Изменить локаль существующего кластера нельзя.
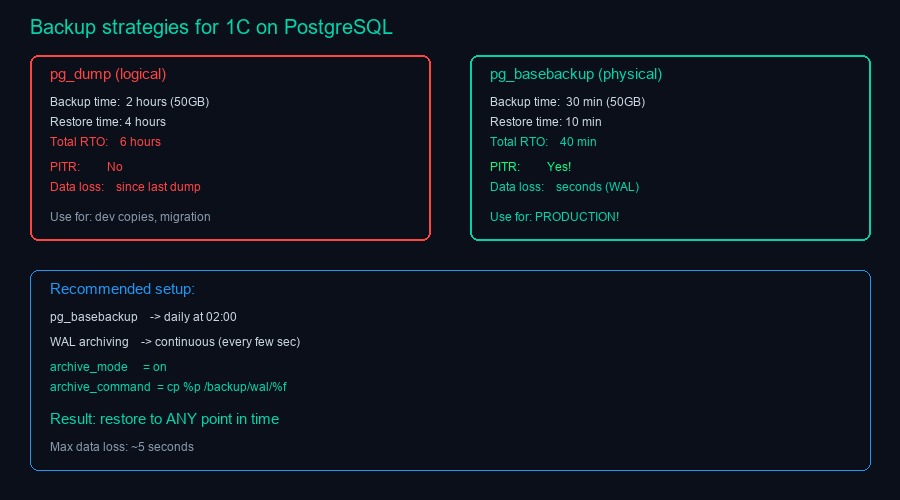
Грабли пятые: бэкапы через pg_dump — не бэкапы
pg_dump создаёт логический дамп базы. Для маленьких баз — нормально. Для базы 1С на 50 ГБ — pg_dump работает два часа и создаёт файл, из которого восстановление займёт четыре часа. Шесть часов простоя при аварии.
Альтернатива — pg_basebackup. Физический бэкап всего кластера. Работает быстрее, восстановление — минуты (просто скопировать файлы и запустить). Плюс — поддержка PITR (Point-In-Time Recovery): можно восстановить базу на любой момент времени, а не только на момент бэкапа.
Для production-серверов 1С на PostgreSQL — только pg_basebackup с WAL-архивированием. Настройка: archive_mode = on, archive_command = копирование WAL-файлов в отдельное хранилище. Бэкап раз в сутки, WAL-файлы копируются непрерывно. Максимальная потеря данных — последние несколько секунд.
pg_dump оставить для переноса данных между серверами и для создания копий для тестирования. Не для бэкапов production.
Стоит ли переезжать
Да, если готовы потратить время на настройку. PostgreSQL для 1С работает. На некоторых нагрузках — даже быстрее SQL Server. Но из коробки — нет. Нужна настройка под конкретную базу, конкретную нагрузку, конкретное железо.
Экономия на лицензиях SQL Server — сотни тысяч рублей в год. Настройка PostgreSQL — два-три дня работы специалиста. Математика простая. Но эти два-три дня нужны. Без них получите базу, которая работает медленнее, чем на SQL Server, и клиент скажет: «Верните как было».
Мы переводили на PostgreSQL около десяти баз за последние два года. Ни одна не вернулась обратно. Но каждая потребовала настройки. Волшебной кнопки «переехать и забыть» не существует.